 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic-Aligned Adversarial Evolution Triangle for High-Transferability Vision-Language Attack
Paper and Code
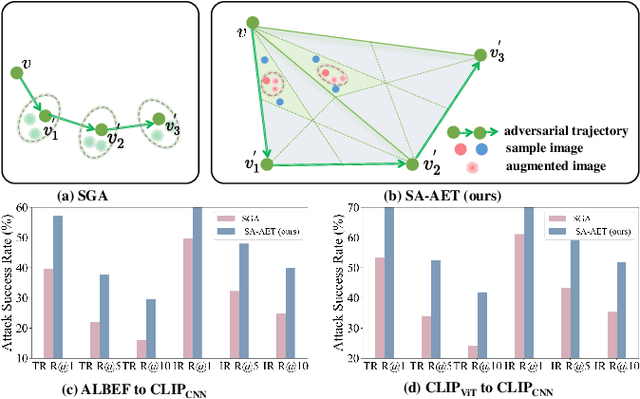


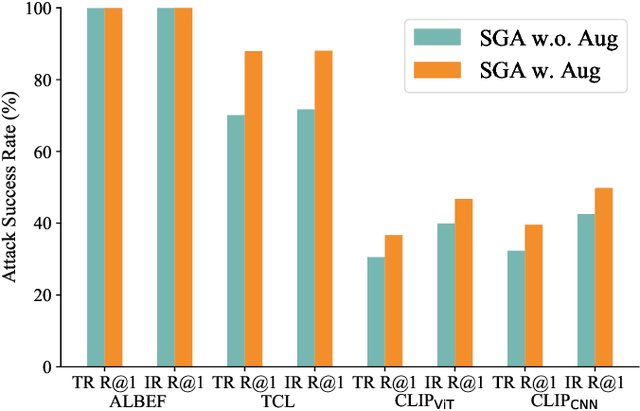
Vision-language pre-training (VLP) models excel at interpreting both images and text but remain vulnerable to multimodal adversarial examples (AEs). Advancing the generation of transferable AEs, which succeed across unseen models, is key to developing more robust and practical VLP models. Previous approaches augment image-text pairs to enhance diversity within the adversarial example generation process, aiming to improve transferability by expanding the contrast space of image-text features. However, these methods focus solely on diversity around the current AEs, yielding limited gains in transferability. To address this issue, we propose to increase the diversity of AEs by leveraging the intersection regions along the adversarial trajectory during optimization. Specifically, we propose sampling from adversarial evolution triangles composed of clean, historical, and current adversarial examples to enhance adversarial diversity. We provide a theoretical analysis to demonstrate the effectiveness of the proposed adversarial evolution triangle. Moreover, we find that redundant inactive dimensions can dominate similarity calculations, distorting feature matching and making AEs model-dependent with reduced transferability. Hence, we propose to generate AEs in the semantic image-text feature contrast space, which can project the original feature space into a semantic corpus subspace. The proposed semantic-aligned subspace can reduce the image feature redundancy, thereby improving adversarial transferability. Extensive experiments across different datasets and models demonstrate that the proposed method can effectively improve adversarial transferability and outperform state-of-the-art adversarial attack methods. The code is released at https://github.com/jiaxiaojunQAQ/SA-AET.