 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-Contrastive Learning for Backdoor Defense
Paper and Code

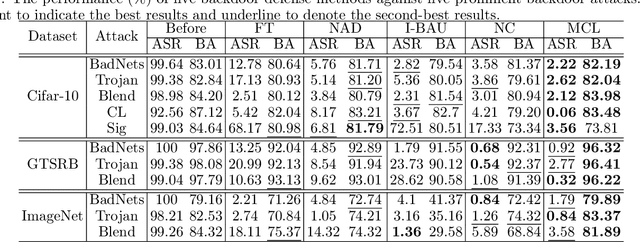

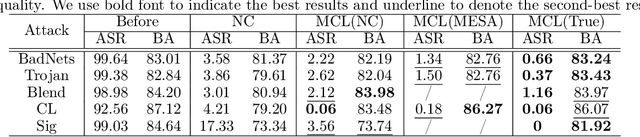
Due to the popularity of Artificial Intelligence (AI) techniques, we are witnessing an increasing number of backdoor injection attacks that are designed to maliciously threaten Deep Neural Networks (DNNs) causing misclassification. Although there exist various defense methods that can effectively erase backdoors from DNNs, they greatly suffer from both high Attack Success Rate (ASR) and a non-negligible loss in Benign Accuracy (BA). Inspired by the observation that a backdoored DNN tends to form a new cluster in its feature spaces for poisoned data, in this paper we propose a novel two-stage backdoor defense method, named MCLDef, based on Model-Contrastive Learning (MCL). In the first stage, our approach performs trigger inversion based on trigger synthesis, where the resultant trigger can be used to generate poisoned data. In the second stage, under the guidance of MCL and our defined positive and negative pairs, MCLDef can purify the backdoored model by pulling the feature representations of poisoned data towards those of their clean data counterparts. Due to the shrunken cluster of poisoned data, the backdoor formed by end-to-end supervised learning is eliminated. Comprehensive experimental results show that, with only 5% of clean data, MCLDef significantly outperforms state-of-the-art defense methods by up to 95.79% reduction in ASR, while in most cases the BA degradation can be controlled within less than 2%. Our code is available at https://github.com/WeCanShow/MCL.