 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Smart Contract Vulnerability Detection via Contrastive Learning-Enhanced Granular-ball Training
Mar 29, 2026Deep neural networks (DNNs) have emerged as a prominent approach for detecting smart contract vulnerabilities, driven by the growing contract datasets and advanced deep learning techniques. However, DNNs typically require large-scale labeled datasets to model the relationships between contract features and vulnerability labels. In practice, the labeling process often depends on existing open-sourced tools, whose accuracy cannot be guaranteed. Consequently, label noise poses a significant challenge for the accuracy and robustness of the smart contract, which is rarely explored in the literature. To this end, we propose Contrastive learning-enhanced Granular-Ball smart Contracts training, CGBC, to enhance the robustness of contract vulnerability detection. Specifically, CGBC first introduces a Granular-ball computing layer between the encoder layer and the classifier layer, to group similar contracts into Granular-Balls (GBs) and generate new coarse-grained representations (i.e., the center and the label of GBs) for them, which can correct noisy labels based on the most correct samples. An inter-GB compactness loss and an intra-GB looseness loss are combined to enhance the effectiveness of clustering. Then, to improve the accuracy of GBs, we pretrain the model through unsupervised contrastive learning supported by our novel semantic-consistent smart contract augmentation method. This procedure can discriminate contracts with different labels by dragging the representation of similar contracts closer, assisting CGBC in clustering. Subsequently, we leverage the symmetric cross-entropy loss function to measure the model quality, which can combat the label noise in gradient computations. Finally, extensive experiments show that the proposed CGBC can significantly improve the robustness and effectiveness of the smart contract vulnerability detection when contrasted with baselines.
An Empirical Study of Vulnerability Detection using Federated Learning
Nov 25, 2024Although Deep Learning (DL) methods becoming increasingly popular in vulnerability detection, their performance is seriously limited by insufficient training data. This is mainly because few existing software organizations can maintain a complete set of high-quality samples for DL-based vulnerability detection. Due to the concerns about privacy leakage, most of them are reluctant to share data, resulting in the data silo problem. Since enables collaboratively model training without data sharing, Federated Learning (FL) has been investigated as a promising means of addressing the data silo problem in DL-based vulnerability detection. However, since existing FL-based vulnerability detection methods focus on specific applications, it is still far unclear i) how well FL adapts to common vulnerability detection tasks and ii) how to design a high-performance FL solution for a specific vulnerability detection task. To answer these two questions, this paper first proposes VulFL, an effective evaluation framework for FL-based vulnerability detection. Then, based on VulFL, this paper conducts a comprehensive study to reveal the underlying capabilities of FL in dealing with different types of CWEs, especially when facing various data heterogeneity scenarios. Our experimental results show that, compared to independent training, FL can significantly improve the detection performance of common AI models on all investigated CWEs, though the performance of FL-based vulnerability detection is limited by heterogeneous data. To highlight the performance differences between different FL solutions for vulnerability detection, we extensively investigate the impacts of different configuration strategies for each framework component of VulFL. Our study sheds light on the potential of FL in vulnerability detection, which can be used to guide the design of FL-based solutions for vulnerability detection.
Multi-Programming Language Sandbox for LLMs
Oct 30, 2024



We introduce MPLSandbox, an out-of-the-box multi-programming language sandbox designed to provide unified and comprehensive feedback from compiler and analysis tools for Large Language Models (LLMs). It can automatically identify the programming language of the code, compiling and executing it within an isolated sub-sandbox to ensure safety and stability. In addition, MPLSandbox also integrates both traditional and LLM-based code analysis tools, providing a comprehensive analysis of generated code. MPLSandbox can be effortlessly integrated into the training and deployment of LLMs to improve the quality and correctness of their generated code. It also helps researchers streamline their workflows for various LLM-based code-related tasks, reducing the development cost. To validate the effectiveness of MPLSandbox, we integrate it into training and deployment approaches, and also employ it to optimize workflows for a wide range of real-world code-related tasks. Our goal is to enhance researcher productivity on LLM-based code-related tasks by simplifying and automating workflows through delegation to MPLSandbox.
What's Wrong with Your Code Generated by Large Language Models? An Extensive Study
Jul 08, 2024
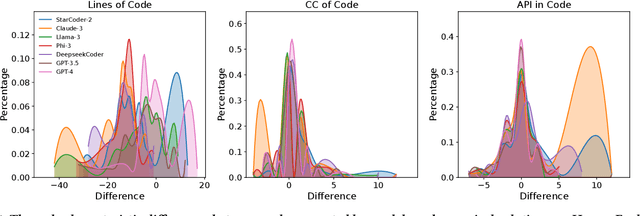


The increasing development of large language models (LLMs) in code generation has drawn significant attention among researchers. To enhance LLM-based code generation ability, current efforts are predominantly directed towards collecting high-quality datasets and leveraging diverse training technologies. However, there is a notable lack of comprehensive studies examining the limitations and boundaries of these existing methods. To bridge this gap, we conducted an extensive empirical study evaluating the performance of three leading closed-source LLMs and four popular open-source LLMs on three commonly used benchmarks. Our investigation, which evaluated the length, cyclomatic complexity and API number of the generated code, revealed that these LLMs face challenges in generating successful code for more complex problems, and tend to produce code that is shorter yet more complicated as compared to canonical solutions. Additionally, we developed a taxonomy of bugs for incorrect codes that includes three categories and 12 sub-categories, and analyze the root cause for common bug types. Furthermore, to better understand the performance of LLMs in real-world projects, we manually created a real-world benchmark comprising 140 code generation tasks. Our analysis highlights distinct differences in bug distributions between actual scenarios and existing benchmarks. Finally, we propose a novel training-free iterative method that introduces self-critique, enabling LLMs to critique and correct their generated code based on bug types and compiler feedback. Experimental results demonstrate that our approach can significantly mitigate bugs and increase the passing rate by 29.2% after two iterations, indicating substantial potential for LLMs to handle more complex problems.
Decorrelate Irrelevant, Purify Relevant: Overcome Textual Spurious Correlations from a Feature Perspective
Feb 16, 2022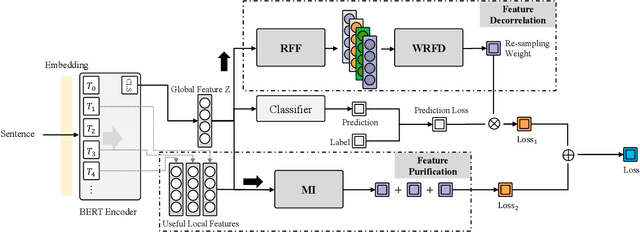
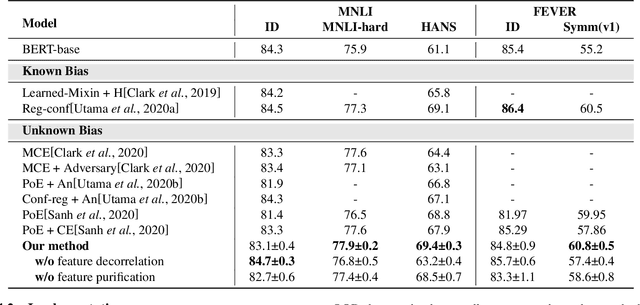
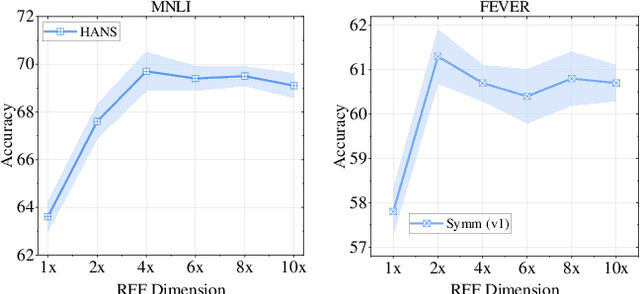
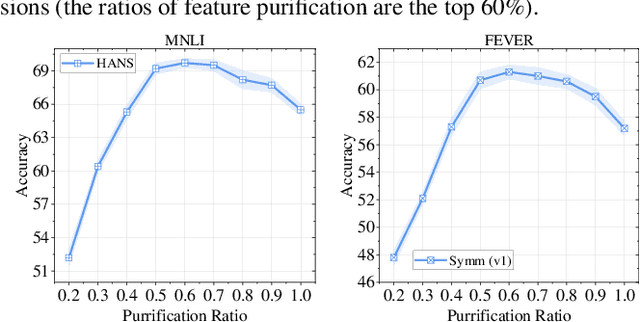
Natural language understanding (NLU) models tend to rely on spurious correlations (\emph{i.e.}, dataset bias) to achieve high performance on in-distribution datasets but poor performance on out-of-distribution ones. Most of the existing debiasing methods often identify and weaken these samples with biased features (\emph{i.e.}, superficial surface features that cause such spurious correlations). However, down-weighting these samples obstructs the model in learning from the non-biased parts of these samples. To tackle this challenge, in this paper, we propose to eliminate spurious correlations in a fine-grained manner from a feature space perspective. Specifically, we introduce Random Fourier Features and weighted re-sampling to decorrelate the dependencies between features to mitigate spurious correlations. After obtaining decorrelated features, we further design a mutual-information-based method to purify them, which forces the model to learn features that are more relevant to tasks. Extensive experiments on two well-studied NLU tasks including Natural Language Inference and Fact Verification demonstrate that our method is superior to other comparative approaches.