 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Epoch Adaptive Rollout Optimization for RL Post-Training
Jun 04, 2026LLM post-training often relies on reinforcement learning methods that sample multiple rollouts per prompt, yet most existing approaches use a fixed rollout budget for every prompt, despite large differences in the training signal different prompts provide. In this paper, we study adaptive rollout allocation under a fixed global budget and formulate the problem as online resource allocation with prompt-level diminishing returns. Our method, CERO, maintains a Beta posterior over each prompt's success probability and uses the posterior expected Bernoulli variance as a Bayesian estimate of the value of additional rollouts. We use this estimate to construct a concave, saturating utility over cumulative allocations, yielding an objective in which decisions across prompts and epochs are coupled by the global budget. Since the resulting objective is temporally nonseparable, we derive a Fenchel-dual reformulation and update both prompt-level and budget-level dual variables via projected online gradient descent. Under fixed prompt utilities, we prove an $O(\sqrt{K})$ regret bound against the offline allocation benchmark. Experiments on mathematical-reasoning problems show that CERO consistently outperforms GRPO across multiple open-weight LLMs and benchmarks, demonstrating that adaptive rollout budgeting can improve sample efficiency.
AgentSchool: An LLM-Powered Multi-Agent Simulation for Education
May 28, 2026Despite the rapid deployment of LLMs into classrooms, validating educational AI remains uniquely intractable: interventions act on developing learners whose cognitive and social trajectories are irreversibly shaped, while real-world trials are slow, ethically constrained, and institutionally locked. LLM-based educational simulators have emerged as a potential remedy, but many still collapse learning into persona-conditioned role-play and, when optimized only to reproduce existing classrooms, can structurally penalize the institutional novelty that pedagogical reform requires. In this work, we introduce AgentSchool, an LLM-driven multi-agent simulator that models learning as state transition rather than prompted behavior. AgentSchool couples cognitively growable student agents -- equipped with weighted subject knowledge graphs, thinking-workflow pools, and explicit misconceptions -- with adaptive teacher agents that plan, scaffold, and reflect along the Zone of Proximal Development, embedded in a configurable scenery generator that situates instruction within both formal and informal learning fields, and a multi-scale simulator that decouples interaction scale, temporal granularity, and simulation duration. Experiments show that structured student agents produce more differentiated mastery and misconception traces than a baseline simulator, while teacher-agent comparisons show backbone-dependent patterns consistent with ZPD-informed adaptation. Further, AgentSchool generates plausible traces of peripheral participation, clique formation, aggressor-induced cohesion, and opinion-leader emergence consistent with classroom social theories. Beyond its role as an educational research instrument, AgentSchool frames education as a socially meaningful testbed for long-horizon memory, multi-agent coordination, and future institutional reasoning under organizational pressure.
SafeWork-R1: Coevolving Safety and Intelligence under the AI-45$^{\circ}$ Law
Jul 24, 2025



We introduce SafeWork-R1, a cutting-edge multimodal reasoning model that demonstrates the coevolution of capabilities and safety. It is developed by our proposed SafeLadder framework, which incorporates large-scale, progressive, safety-oriented reinforcement learning post-training, supported by a suite of multi-principled verifiers. Unlike previous alignment methods such as RLHF that simply learn human preferences, SafeLadder enables SafeWork-R1 to develop intrinsic safety reasoning and self-reflection abilities, giving rise to safety `aha' moments. Notably, SafeWork-R1 achieves an average improvement of $46.54\%$ over its base model Qwen2.5-VL-72B on safety-related benchmarks without compromising general capabilities, and delivers state-of-the-art safety performance compared to leading proprietary models such as GPT-4.1 and Claude Opus 4. To further bolster its reliability, we implement two distinct inference-time intervention methods and a deliberative search mechanism, enforcing step-level verification. Finally, we further develop SafeWork-R1-InternVL3-78B, SafeWork-R1-DeepSeek-70B, and SafeWork-R1-Qwen2.5VL-7B. All resulting models demonstrate that safety and capability can co-evolve synergistically, highlighting the generalizability of our framework in building robust, reliable, and trustworthy general-purpose AI.
Adaptive Bidding Policies for First-Price Auctions with Budget Constraints under Non-stationarity
May 05, 2025We study how a budget-constrained bidder should learn to adaptively bid in repeated first-price auctions to maximize her cumulative payoff. This problem arose due to an industry-wide shift from second-price auctions to first-price auctions in display advertising recently, which renders truthful bidding (i.e., always bidding one's private value) no longer optimal. We propose a simple dual-gradient-descent-based bidding policy that maintains a dual variable for budget constraint as the bidder consumes her budget. In analysis, we consider two settings regarding the bidder's knowledge of her private values in the future: (i) an uninformative setting where all the distributional knowledge (can be non-stationary) is entirely unknown to the bidder, and (ii) an informative setting where a prediction of the budget allocation in advance. We characterize the performance loss (or regret) relative to an optimal policy with complete information on the stochasticity. For uninformative setting, We show that the regret is \tilde{O}(\sqrt{T}) plus a variation term that reflects the non-stationarity of the value distributions, and this is of optimal order. We then show that we can get rid of the variation term with the help of the prediction; specifically, the regret is \tilde{O}(\sqrt{T}) plus the prediction error term in the informative setting.
Holistic Audit Dataset Generation for LLM Unlearning via Knowledge Graph Traversal and Redundancy Removal
Feb 26, 2025In recent years, Large Language Models (LLMs) have faced increasing demands to selectively remove sensitive information, protect privacy, and comply with copyright regulations through unlearning, by Machine Unlearning. While evaluating unlearning effectiveness is crucial, existing benchmarks are limited in scale and comprehensiveness, typically containing only a few hundred test cases. We identify two critical challenges in generating holistic audit datasets: ensuring audit adequacy and handling knowledge redundancy between forget and retain dataset. To address these challenges, we propose HANKER, an automated framework for holistic audit dataset generation leveraging knowledge graphs to achieve fine-grained coverage and eliminate redundant knowledge. Applying HANKER to the popular MUSE benchmark, we successfully generated over 69,000 and 111,000 audit cases for the News and Books datasets respectively, identifying thousands of knowledge memorization instances that the previous benchmark failed to detect. Our empirical analysis uncovers how knowledge redundancy significantly skews unlearning effectiveness metrics, with redundant instances artificially inflating the observed memorization measurements ROUGE from 19.7% to 26.1% and Entailment Scores from 32.4% to 35.2%, highlighting the necessity of systematic deduplication for accurate assessment.
CloudAttention: Efficient Multi-Scale Attention Scheme For 3D Point Cloud Learning
Jul 31, 2022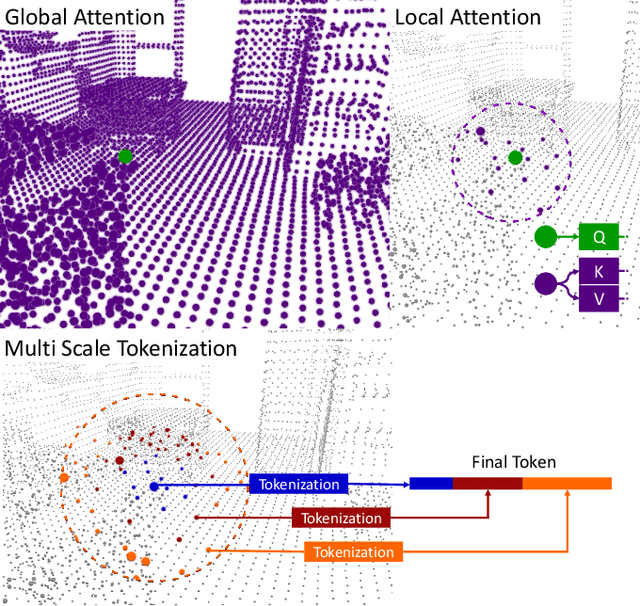
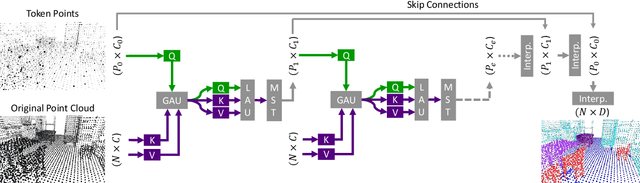
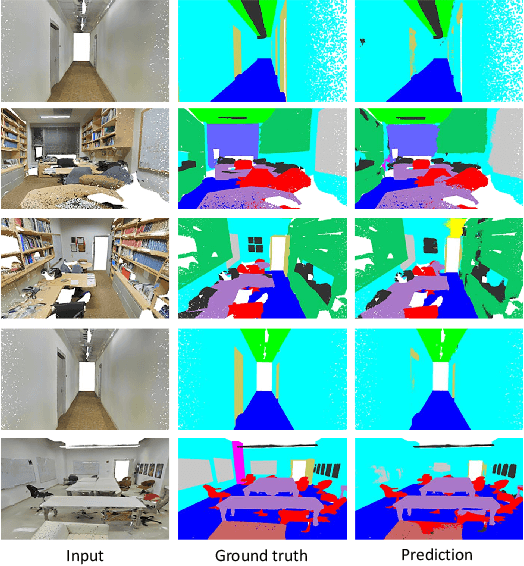

Processing 3D data efficiently has always been a challenge. Spatial operations on large-scale point clouds, stored as sparse data, require extra cost. Attracted by the success of transformers, researchers are using multi-head attention for vision tasks. However, attention calculations in transformers come with quadratic complexity in the number of inputs and miss spatial intuition on sets like point clouds. We redesign set transformers in this work and incorporate them into a hierarchical framework for shape classification and part and scene segmentation. We propose our local attention unit, which captures features in a spatial neighborhood. We also compute efficient and dynamic global cross attentions by leveraging sampling and grouping at each iteration. Finally, to mitigate the non-heterogeneity of point clouds, we propose an efficient Multi-Scale Tokenization (MST), which extracts scale-invariant tokens for attention operations. The proposed hierarchical model achieves state-of-the-art shape classification in mean accuracy and yields results on par with the previous segmentation methods while requiring significantly fewer computations. Our proposed architecture predicts segmentation labels with around half the latency and parameter count of the previous most efficient method with comparable performance. The code is available at https://github.com/YigeWang-WHU/CloudAttention.
Hierarchical Feature Embedding for Attribute Recognition
May 23, 2020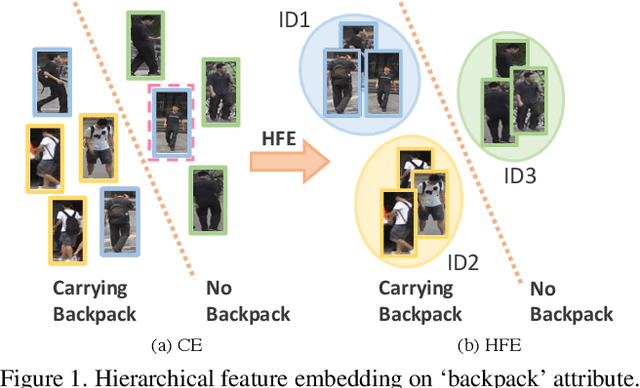

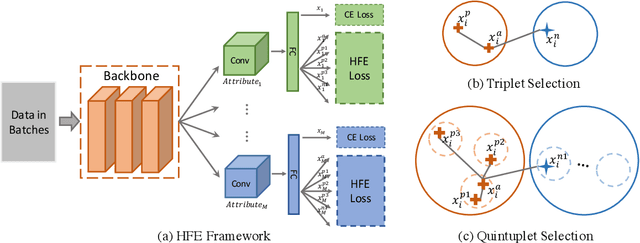
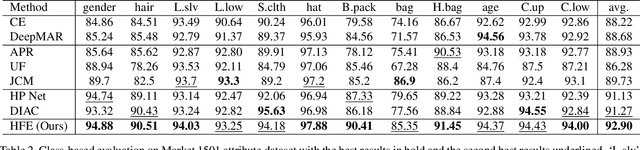
Attribute recognition is a crucial but challenging task due to viewpoint changes, illumination variations and appearance diversities, etc. Most of previous work only consider the attribute-level feature embedding, which might perform poorly in complicated heterogeneous conditions. To address this problem, we propose a hierarchical feature embedding (HFE) framework, which learns a fine-grained feature embedding by combining attribute and ID information. In HFE, we maintain the inter-class and intra-class feature embedding simultaneously. Not only samples with the same attribute but also samples with the same ID are gathered more closely, which could restrict the feature embedding of visually hard samples with regard to attributes and improve the robustness to variant conditions. We establish this hierarchical structure by utilizing HFE loss consisted of attribute-level and ID-level constraints. We also introduce an absolute boundary regularization and a dynamic loss weight as supplementary components to help build up the feature embedding. Experiments show that our method achieves the state-of-the-art results on two pedestrian attribute datasets and a facial attribute dataset.