 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating the Effectiveness of HyperTuning via Gisting
Paper and Code
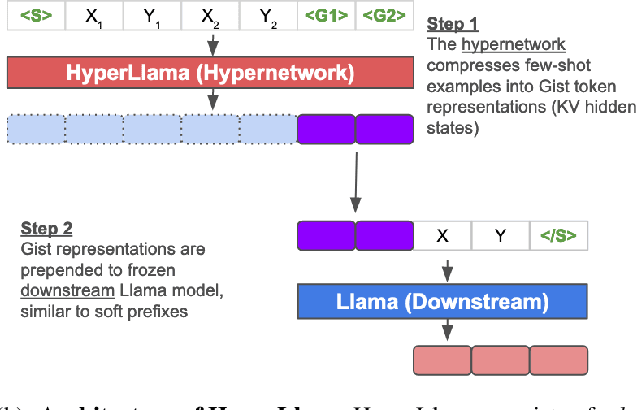
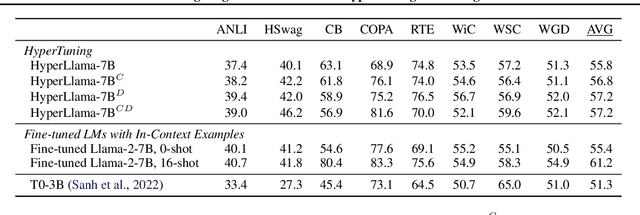
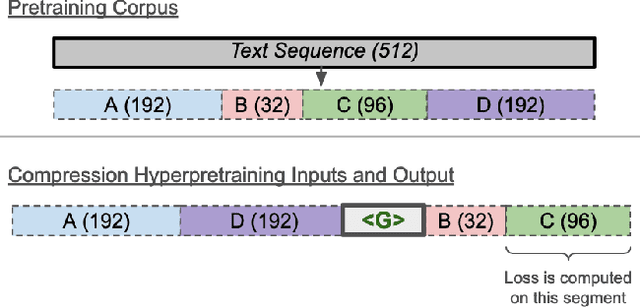

Gisting (Mu et al., 2023) is a simple method for training models to compress information into fewer token representations using a modified attention mask, and can serve as an economical approach to training Transformer-based hypernetworks. We introduce HyperLlama, a set of Gisting-based hypernetworks built on Llama-2 models that generates task-specific soft prefixes based on few-shot inputs. In experiments across P3, Super-NaturalInstructions and Symbol Tuning datasets, we show that HyperLlama models can effectively compress information from few-shot examples into soft prefixes. However, they still underperform multi-task fine-tuned language models with full attention over few-shot in-context examples. We also show that HyperLlama-generated soft prefixes can serve as better initializations for further prefix tuning. Overall, Gisting-based hypernetworks are economical and easy to implement, but have mixed empirical performance.