 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStruc-Bench: Are Large Language Models Really Good at Generating Complex Structured Data?
Paper and Code

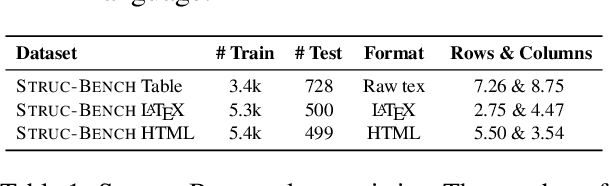
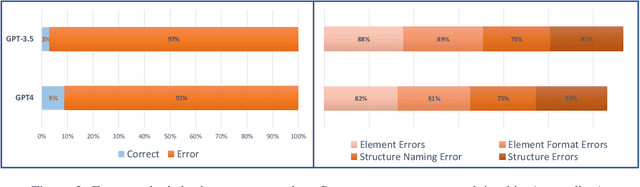
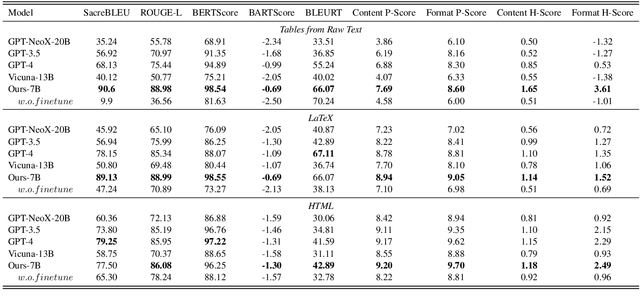
Despite the power of Large Language Models (LLMs) like GPT-4, they still struggle with tasks that require generating complex, structured outputs. In this study, we assess the capability of Current LLMs in generating complex structured data and propose a structure-aware fine-tuning approach as a solution to improve this ability. To perform a comprehensive evaluation, we propose Struc-Bench, include five representative LLMs (i.e., GPT-NeoX 20B, GPT-3.5, GPT-4, and Vicuna) and evaluate them on our carefully constructed datasets spanning raw text, HTML, and LaTeX tables. Based on our analysis of current model performance, we identify specific common formatting errors and areas of potential improvement. To address complex formatting requirements, we utilize FormatCoT (Chain-of-Thought) to generate format instructions from target outputs. Our experiments show that our structure-aware fine-tuning method, when applied to LLaMA-7B, significantly improves adherence to natural language constraints, outperforming other evaluated LLMs. Based on these results, we present an ability map of model capabilities from six dimensions (i.e., coverage, formatting, reasoning, comprehension, pragmatics, and hallucination). This map highlights the weaknesses of LLMs in handling complex structured outputs and suggests promising directions for future work. Our code and models can be found at https://github.com/gersteinlab/Struc-Bench.