 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Semi-infinite Linear Programming: Efficient Algorithms via Function Approximation
Mar 17, 2026We consider the dynamic resource allocation problem where the decision space is finite-dimensional, yet the solution must satisfy a large or even infinite number of constraints revealed via streaming data or oracle feedback. We model this challenge as an Online Semi-infinite Linear Programming (OSILP) problem and develop a novel LP formulation to solve it approximately. Specifically, we employ function approximation to reduce the number of constraints to a constant $q$. This addresses a key limitation of traditional online LP algorithms, whose regret bounds typically depend on the number of constraints, leading to poor performance in this setting. We propose a dual-based algorithm to solve our new formulation, which offers broad applicability through the selection of appropriate potential functions. We analyze this algorithm under two classical input models-stochastic input and random permutation-establishing regret bounds of $O(q\sqrt{T})$ and $O\left(\left(q+q\log{T})\sqrt{T}\right)\right)$ respectively. Note that both regret bounds are independent of the number of constraints, which demonstrates the potential of our approach to handle a large or infinite number of constraints. Furthermore, we investigate the potential to improve upon the $O(q\sqrt{T})$ regret and propose a two-stage algorithm, achieving $O(q\log{T} + q/ε)$ regret under more stringent assumptions. We also extend our algorithms to the general function setting. A series of experiments validates that our algorithms outperform existing methods when confronted with a large number of constraints.
Adaptive Resolving Methods for Reinforcement Learning with Function Approximations
May 17, 2025


Reinforcement learning (RL) problems are fundamental in online decision-making and have been instrumental in finding an optimal policy for Markov decision processes (MDPs). Function approximations are usually deployed to handle large or infinite state-action space. In our work, we consider the RL problems with function approximation and we develop a new algorithm to solve it efficiently. Our algorithm is based on the linear programming (LP) reformulation and it resolves the LP at each iteration improved with new data arrival. Such a resolving scheme enables our algorithm to achieve an instance-dependent sample complexity guarantee, more precisely, when we have $N$ data, the output of our algorithm enjoys an instance-dependent $\tilde{O}(1/N)$ suboptimality gap. In comparison to the $O(1/\sqrt{N})$ worst-case guarantee established in the previous literature, our instance-dependent guarantee is tighter when the underlying instance is favorable, and the numerical experiments also reveal the efficient empirical performances of our algorithms.
ML-Bench: Large Language Models Leverage Open-source Libraries for Machine Learning Tasks
Nov 16, 2023



Large language models have shown promising performance in code generation benchmarks. However, a considerable divide exists between these benchmark achievements and their practical applicability, primarily attributed to real-world programming's reliance on pre-existing libraries. Instead of evaluating LLMs to code from scratch, this work aims to propose a new evaluation setup where LLMs use open-source libraries to finish machine learning tasks. Therefore, we propose ML-Bench, an expansive benchmark developed to assess the effectiveness of LLMs in leveraging existing functions in open-source libraries. Consisting of 10044 samples spanning 130 tasks over 14 notable machine learning GitHub repositories. In this setting, given a specific machine learning task instruction and the accompanying README in a codebase, an LLM is tasked to generate code to accomplish the task. This necessitates the comprehension of long and language-code interleaved documents, as well as the understanding of complex cross-file code structures, introducing new challenges. Notably, while GPT-4 exhibits remarkable improvement over other LLMs, it manages to accomplish only 39.73\% of the tasks, leaving a huge space for improvement. We address these challenges by proposing ML-Agent, designed to effectively navigate the codebase, locate documentation, retrieve code, and generate executable code. Empirical results demonstrate that ML-Agent, built upon GPT-4, results in further improvements. Code, data, and models are available at \url{https://ml-bench.github.io/}.
Struc-Bench: Are Large Language Models Really Good at Generating Complex Structured Data?
Sep 19, 2023
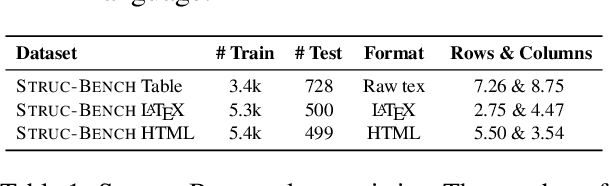
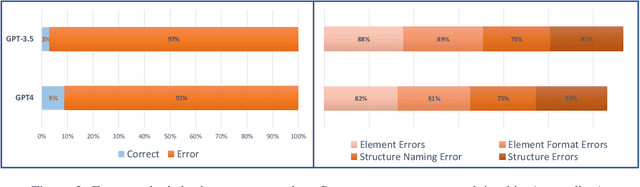
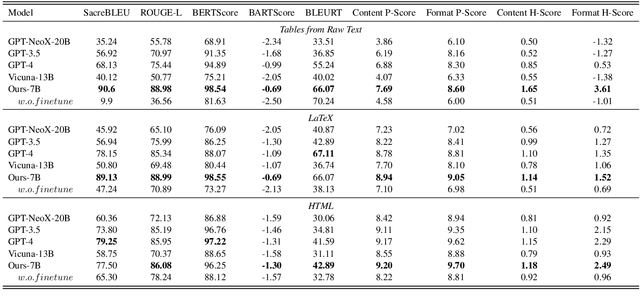
Despite the power of Large Language Models (LLMs) like GPT-4, they still struggle with tasks that require generating complex, structured outputs. In this study, we assess the capability of Current LLMs in generating complex structured data and propose a structure-aware fine-tuning approach as a solution to improve this ability. To perform a comprehensive evaluation, we propose Struc-Bench, include five representative LLMs (i.e., GPT-NeoX 20B, GPT-3.5, GPT-4, and Vicuna) and evaluate them on our carefully constructed datasets spanning raw text, HTML, and LaTeX tables. Based on our analysis of current model performance, we identify specific common formatting errors and areas of potential improvement. To address complex formatting requirements, we utilize FormatCoT (Chain-of-Thought) to generate format instructions from target outputs. Our experiments show that our structure-aware fine-tuning method, when applied to LLaMA-7B, significantly improves adherence to natural language constraints, outperforming other evaluated LLMs. Based on these results, we present an ability map of model capabilities from six dimensions (i.e., coverage, formatting, reasoning, comprehension, pragmatics, and hallucination). This map highlights the weaknesses of LLMs in handling complex structured outputs and suggests promising directions for future work. Our code and models can be found at https://github.com/gersteinlab/Struc-Bench.