 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTree-Guided Diffusion Planner
Aug 29, 2025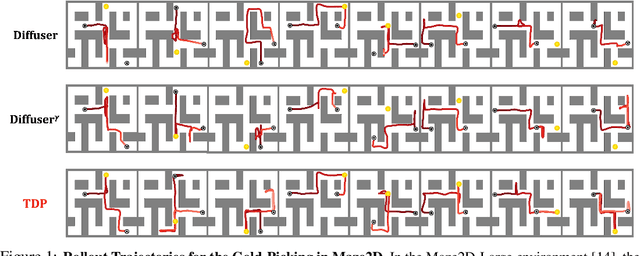
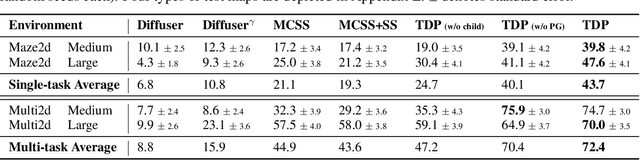
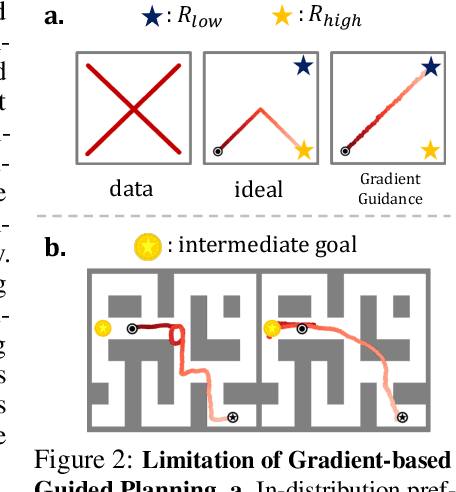

Planning with pretrained diffusion models has emerged as a promising approach for solving test-time guided control problems. However, standard gradient guidance typically performs optimally under convex and differentiable reward landscapes, showing substantially reduced effectiveness in real-world scenarios involving non-convex objectives, non-differentiable constraints, and multi-reward structures. Furthermore, recent supervised planning approaches require task-specific training or value estimators, which limits test-time flexibility and zero-shot generalization. We propose a Tree-guided Diffusion Planner (TDP), a zero-shot test-time planning framework that balances exploration and exploitation through structured trajectory generation. We frame test-time planning as a tree search problem using a bi-level sampling process: (1) diverse parent trajectories are produced via training-free particle guidance to encourage broad exploration, and (2) sub-trajectories are refined through fast conditional denoising guided by task objectives. TDP addresses the limitations of gradient guidance by exploring diverse trajectory regions and harnessing gradient information across this expanded solution space using only pretrained models and test-time reward signals. We evaluate TDP on three diverse tasks: maze gold-picking, robot arm block manipulation, and AntMaze multi-goal exploration. TDP consistently outperforms state-of-the-art approaches on all tasks. The project page can be found at: tree-diffusion-planner.github.io.
ReALFRED: An Embodied Instruction Following Benchmark in Photo-Realistic Environments
Jul 26, 2024

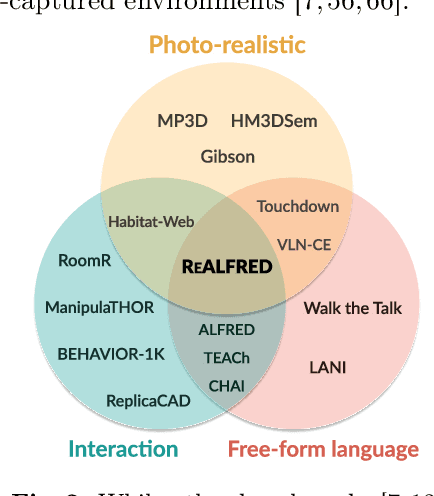

Simulated virtual environments have been widely used to learn robotic agents that perform daily household tasks. These environments encourage research progress by far, but often provide limited object interactability, visual appearance different from real-world environments, or relatively smaller environment sizes. This prevents the learned models in the virtual scenes from being readily deployable. To bridge the gap between these learning environments and deploying (i.e., real) environments, we propose the ReALFRED benchmark that employs real-world scenes, objects, and room layouts to learn agents to complete household tasks by understanding free-form language instructions and interacting with objects in large, multi-room and 3D-captured scenes. Specifically, we extend the ALFRED benchmark with updates for larger environmental spaces with smaller visual domain gaps. With ReALFRED, we analyze previously crafted methods for the ALFRED benchmark and observe that they consistently yield lower performance in all metrics, encouraging the community to develop methods in more realistic environments. Our code and data are publicly available.
Context-Aware Planning and Environment-Aware Memory for Instruction Following Embodied Agents
Aug 22, 2023
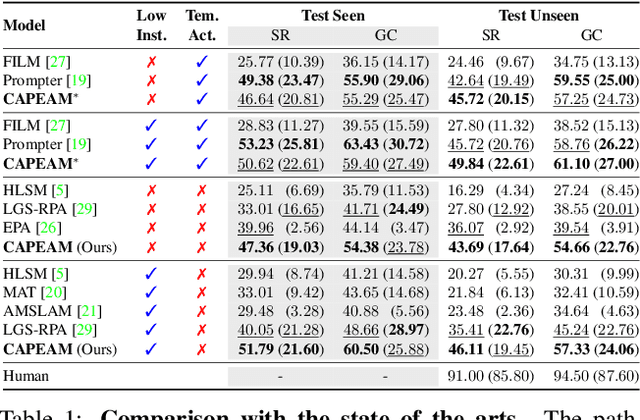

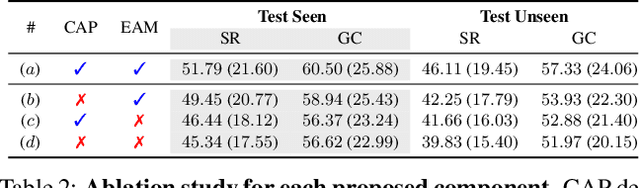
Accomplishing household tasks requires to plan step-by-step actions considering the consequences of previous actions. However, the state-of-the-art embodied agents often make mistakes in navigating the environment and interacting with proper objects due to imperfect learning by imitating experts or algorithmic planners without such knowledge. To improve both visual navigation and object interaction, we propose to consider the consequence of taken actions by CAPEAM (Context-Aware Planning and Environment-Aware Memory) that incorporates semantic context (e.g., appropriate objects to interact with) in a sequence of actions, and the changed spatial arrangement and states of interacted objects (e.g., location that the object has been moved to) in inferring the subsequent actions. We empirically show that the agent with the proposed CAPEAM achieves state-of-the-art performance in various metrics using a challenging interactive instruction following benchmark in both seen and unseen environments by large margins (up to +10.70% in unseen env.).