 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Large Language Models as Generative User Simulators for Conversational Recommendation
Mar 25, 2024
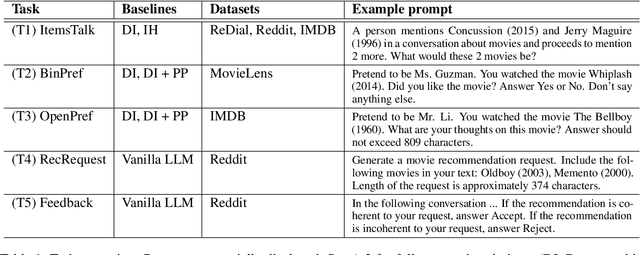
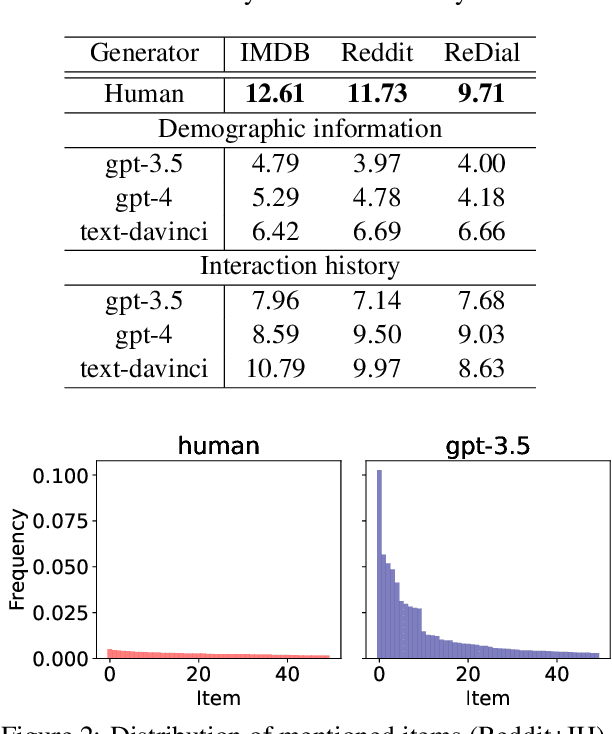
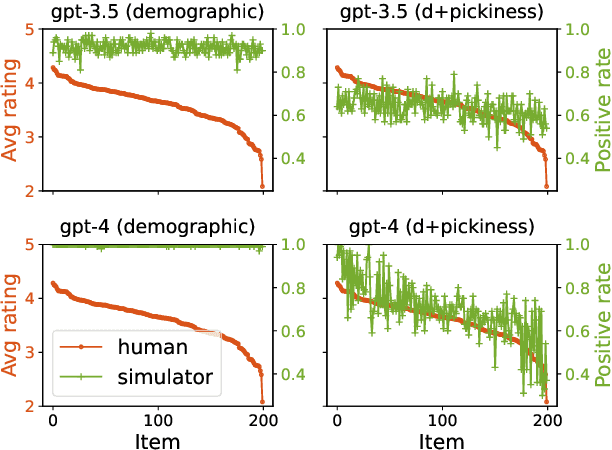
Synthetic users are cost-effective proxies for real users in the evaluation of conversational recommender systems. Large language models show promise in simulating human-like behavior, raising the question of their ability to represent a diverse population of users. We introduce a new protocol to measure the degree to which language models can accurately emulate human behavior in conversational recommendation. This protocol is comprised of five tasks, each designed to evaluate a key property that a synthetic user should exhibit: choosing which items to talk about, expressing binary preferences, expressing open-ended preferences, requesting recommendations, and giving feedback. Through evaluation of baseline simulators, we demonstrate these tasks effectively reveal deviations of language models from human behavior, and offer insights on how to reduce the deviations with model selection and prompting strategies.