 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuto-Encoding or Auto-Regression? A Reality Check on Causality of Self-Attention-Based Sequential Recommenders
Paper and Code


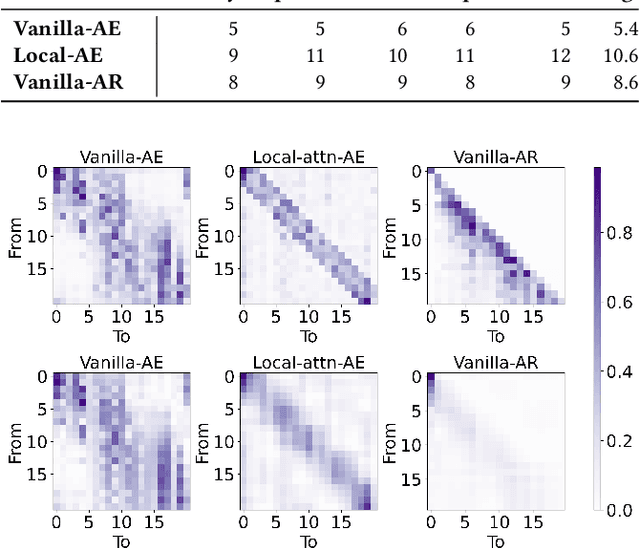

The comparison between Auto-Encoding (AE) and Auto-Regression (AR) has become an increasingly important topic with recent advances in sequential recommendation. At the heart of this discussion lies the comparison of BERT4Rec and SASRec, which serve as representative AE and AR models for self-attentive sequential recommenders. Yet the conclusion of this debate remains uncertain due to: (1) the lack of fair and controlled environments for experiments and evaluations; and (2) the presence of numerous confounding factors w.r.t. feature selection, modeling choices and optimization algorithms. In this work, we aim to answer this question by conducting a series of controlled experiments. We start by tracing the AE/AR debate back to its origin through a systematic re-evaluation of SASRec and BERT4Rec, discovering that AR models generally surpass AE models in sequential recommendation. In addition, we find that AR models further outperforms AE models when using a customized design space that includes additional features, modeling approaches and optimization techniques. Furthermore, the performance advantage of AR models persists in the broader HuggingFace transformer ecosystems. Lastly, we provide potential explanations and insights into AE/AR performance from two key perspectives: low-rank approximation and inductive bias. We make our code and data available at https://github.com/yueqirex/ModSAR