 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow do Humans Understand Explanations from Machine Learning Systems? An Evaluation of the Human-Interpretability of Explanation
Paper and Code
Feb 02, 2018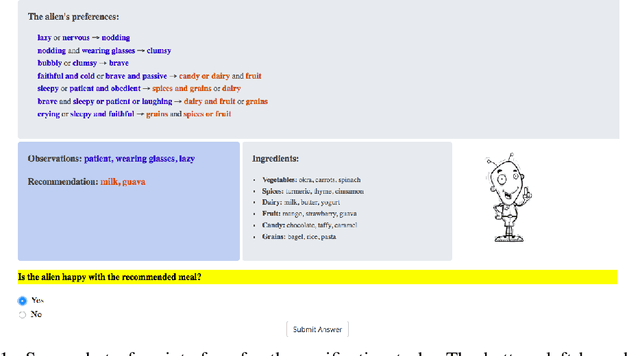
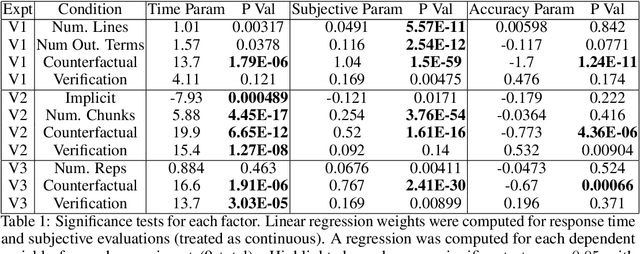
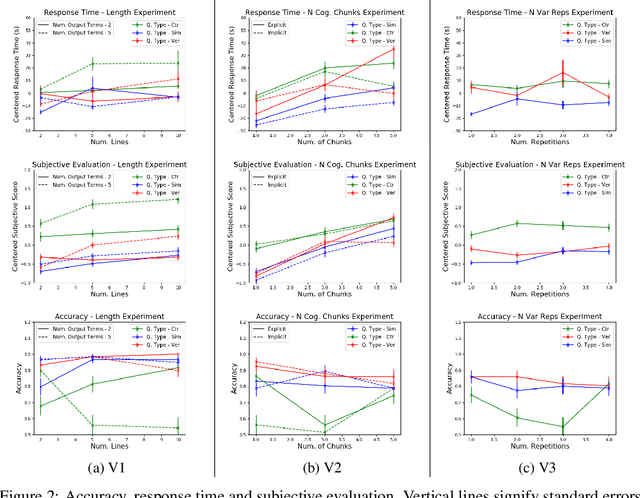
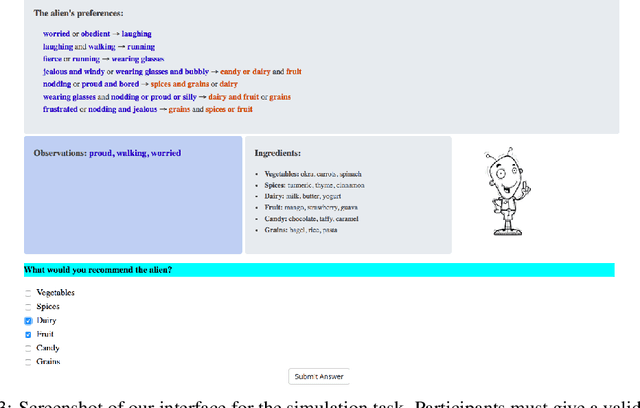
Recent years have seen a boom in interest in machine learning systems that can provide a human-understandable rationale for their predictions or decisions. However, exactly what kinds of explanation are truly human-interpretable remains poorly understood. This work advances our understanding of what makes explanations interpretable in the specific context of verification. Suppose we have a machine learning system that predicts X, and we provide rationale for this prediction X. Given an input, an explanation, and an output, is the output consistent with the input and the supposed rationale? Via a series of user-studies, we identify what kinds of increases in complexity have the greatest effect on the time it takes for humans to verify the rationale, and which seem relatively insensitive.