 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconfidencing LLMs from the Grouping Loss Perspective
Paper and Code
Feb 07, 2024

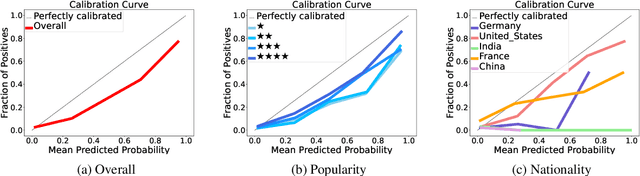

Large Language Models (LLMs), including ChatGPT and LLaMA, are susceptible to generating hallucinated answers in a confident tone. While efforts to elicit and calibrate confidence scores have proven useful, recent findings show that controlling uncertainty must go beyond calibration: predicted scores may deviate significantly from the actual posterior probabilities due to the impact of grouping loss. In this work, we construct a new evaluation dataset derived from a knowledge base to assess confidence scores given to answers of Mistral and LLaMA. Experiments show that they tend to be overconfident. Further, we show that they are more overconfident on some answers than others, \emph{eg} depending on the nationality of the person in the query. In uncertainty-quantification theory, this is grouping loss. To address this, we propose a solution to reconfidence LLMs, canceling not only calibration but also grouping loss. The LLMs, after the reconfidencing process, indicate improved confidence alignment with the accuracy of their responses.