 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph integration of structured, semistructured and unstructured data for data journalism
Dec 16, 2020
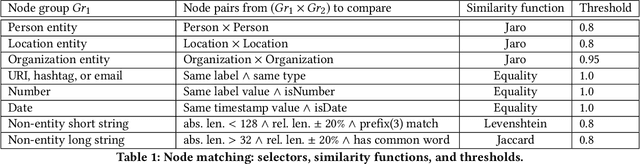
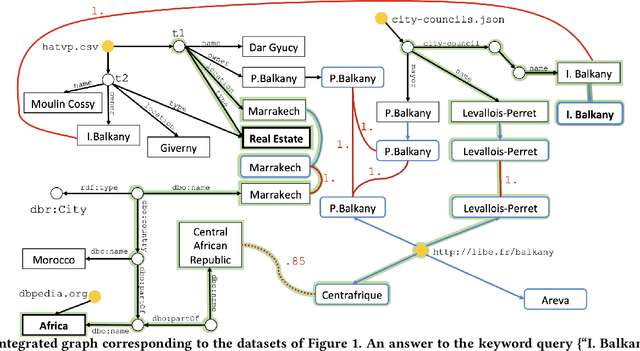

Digital data is a gold mine for modern journalism. However, datasets which interest journalists are extremely heterogeneous, ranging from highly structured (relational databases), semi-structured (JSON, XML, HTML), graphs (e.g., RDF), and text. Journalists (and other classes of users lacking advanced IT expertise, such as most non-governmental-organizations, or small public administrations) need to be able to make sense of such heterogeneous corpora, even if they lack the ability to define and deploy custom extract-transform-load workflows, especially for dynamically varying sets of data sources. We describe a complete approach for integrating dynamic sets of heterogeneous datasets along the lines described above: the challenges we faced to make such graphs useful, allow their integration to scale, and the solutions we proposed for these problems. Our approach is implemented within the ConnectionLens system; we validate it through a set of experiments.
A Labeled Graph Kernel for Relationship Extraction
Feb 20, 2013
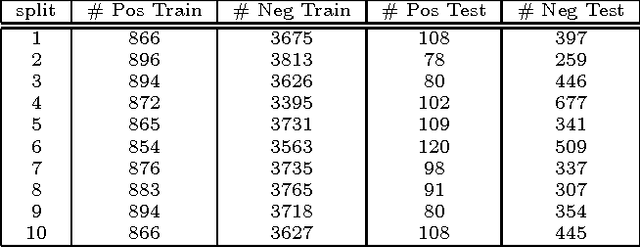

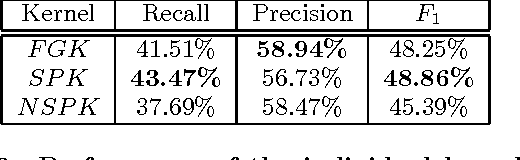
In this paper, we propose an approach for Relationship Extraction (RE) based on labeled graph kernels. The kernel we propose is a particularization of a random walk kernel that exploits two properties previously studied in the RE literature: (i) the words between the candidate entities or connecting them in a syntactic representation are particularly likely to carry information regarding the relationship; and (ii) combining information from distinct sources in a kernel may help the RE system make better decisions. We performed experiments on a dataset of protein-protein interactions and the results show that our approach obtains effectiveness values that are comparable with the state-of-the art kernel methods. Moreover, our approach is able to outperform the state-of-the-art kernels when combined with other kernel methods.