 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Well-Composed Text is Half Done! Composition Sampling for Diverse Conditional Generation
Mar 28, 2022



We propose Composition Sampling, a simple but effective method to generate diverse outputs for conditional generation of higher quality compared to previous stochastic decoding strategies. It builds on recently proposed plan-based neural generation models (Narayan et al, 2021) that are trained to first create a composition of the output and then generate by conditioning on it and the input. Our approach avoids text degeneration by first sampling a composition in the form of an entity chain and then using beam search to generate the best possible text grounded to this entity chain. Experiments on summarization (CNN/DailyMail and XSum) and question generation (SQuAD), using existing and newly proposed automatic metrics together with human-based evaluation, demonstrate that Composition Sampling is currently the best available decoding strategy for generating diverse meaningful outputs.
Text Segmentation by Cross Segment Attention
Apr 30, 2020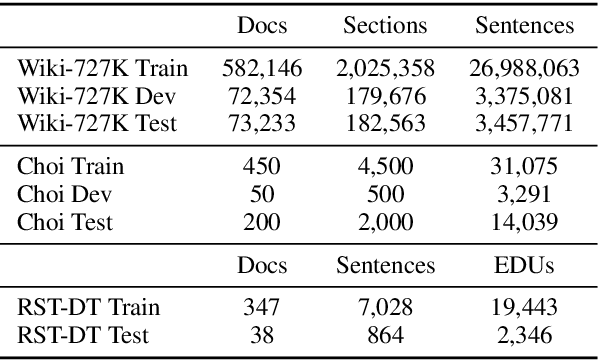
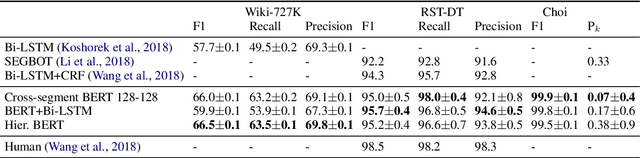
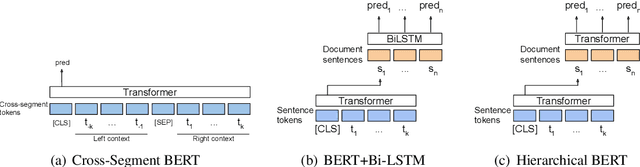
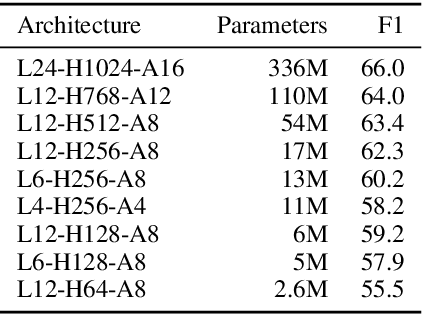
Document and discourse segmentation are two fundamental NLP tasks pertaining to breaking up text into constituents, which are commonly used to help downstream tasks such as information retrieval or text summarization. In this work, we propose three transformer-based architectures and provide comprehensive comparisons with previously proposed approaches on three standard datasets. We establish a new state-of-the-art, reducing in particular the error rates by a large margin in all cases. We further analyze model sizes and find that we can build models with many fewer parameters while keeping good performance, thus facilitating real-world applications.
A Labeled Graph Kernel for Relationship Extraction
Feb 20, 2013
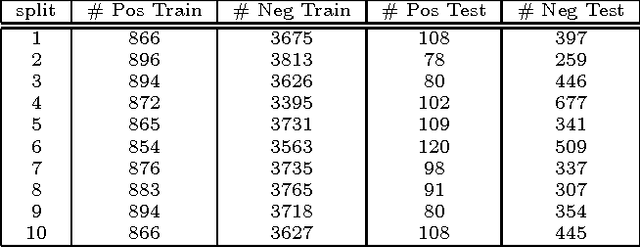

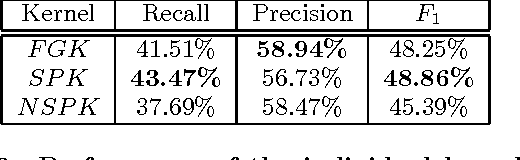
In this paper, we propose an approach for Relationship Extraction (RE) based on labeled graph kernels. The kernel we propose is a particularization of a random walk kernel that exploits two properties previously studied in the RE literature: (i) the words between the candidate entities or connecting them in a syntactic representation are particularly likely to carry information regarding the relationship; and (ii) combining information from distinct sources in a kernel may help the RE system make better decisions. We performed experiments on a dataset of protein-protein interactions and the results show that our approach obtains effectiveness values that are comparable with the state-of-the art kernel methods. Moreover, our approach is able to outperform the state-of-the-art kernels when combined with other kernel methods.