Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Segmentation by Cross Segment Attention
Paper and Code
Apr 30, 2020
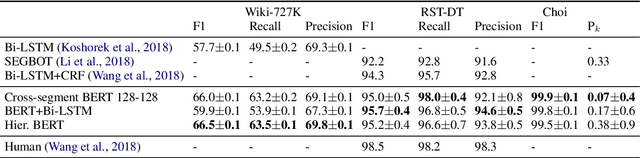
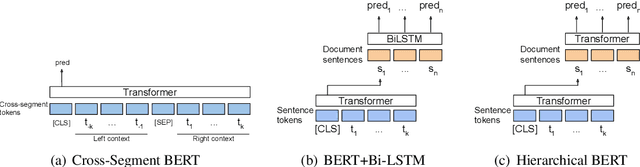
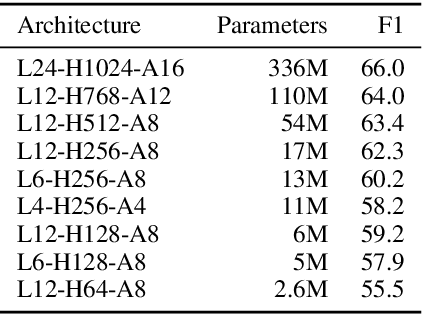
Document and discourse segmentation are two fundamental NLP tasks pertaining to breaking up text into constituents, which are commonly used to help downstream tasks such as information retrieval or text summarization. In this work, we propose three transformer-based architectures and provide comprehensive comparisons with previously proposed approaches on three standard datasets. We establish a new state-of-the-art, reducing in particular the error rates by a large margin in all cases. We further analyze model sizes and find that we can build models with many fewer parameters while keeping good performance, thus facilitating real-world applications.
* 10 pages, 4 figures
View paper on