 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning from Reformulations in Conversational Question Answering over Knowledge Graphs
Paper and Code
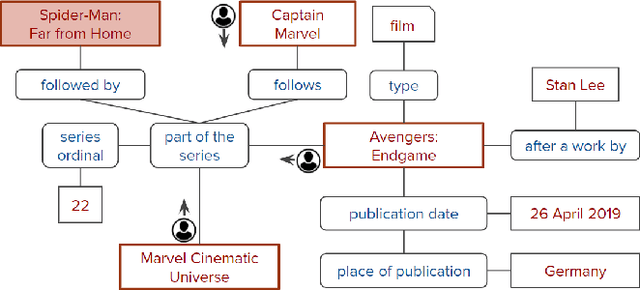

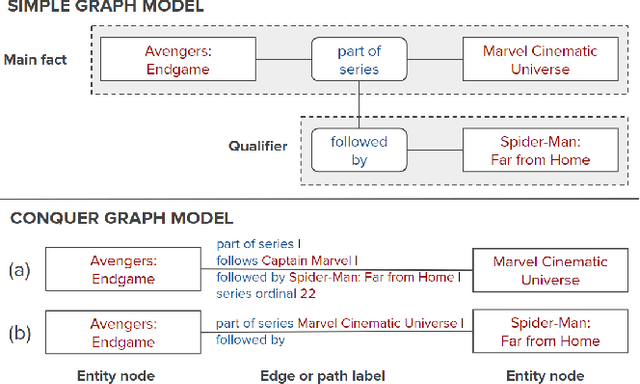

The rise of personal assistants has made conversational question answering (ConvQA) a very popular mechanism for user-system interaction. State-of-the-art methods for ConvQA over knowledge graphs (KGs) can only learn from crisp question-answer pairs found in popular benchmarks. In reality, however, such training data is hard to come by: users would rarely mark answers explicitly as correct or wrong. In this work, we take a step towards a more natural learning paradigm - from noisy and implicit feedback via question reformulations. A reformulation is likely to be triggered by an incorrect system response, whereas a new follow-up question could be a positive signal on the previous turn's answer. We present a reinforcement learning model, termed CONQUER, that can learn from a conversational stream of questions and reformulations. CONQUER models the answering process as multiple agents walking in parallel on the KG, where the walks are determined by actions sampled using a policy network. This policy network takes the question along with the conversational context as inputs and is trained via noisy rewards obtained from the reformulation likelihood. To evaluate CONQUER, we create and release ConvRef, a benchmark with about 11k natural conversations containing around 205k reformulations. Experiments show that CONQUER successfully learns to answer conversational questions from noisy reward signals, significantly improving over a state-of-the-art baseline.