 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnnoCTR: A Dataset for Detecting and Linking Entities, Tactics, and Techniques in Cyber Threat Reports
Apr 11, 2024



Monitoring the threat landscape to be aware of actual or potential attacks is of utmost importance to cybersecurity professionals. Information about cyber threats is typically distributed using natural language reports. Natural language processing can help with managing this large amount of unstructured information, yet to date, the topic has received little attention. With this paper, we present AnnoCTR, a new CC-BY-SA-licensed dataset of cyber threat reports. The reports have been annotated by a domain expert with named entities, temporal expressions, and cybersecurity-specific concepts including implicitly mentioned techniques and tactics. Entities and concepts are linked to Wikipedia and the MITRE ATT&CK knowledge base, the most widely-used taxonomy for classifying types of attacks. Prior datasets linking to MITRE ATT&CK either provide a single label per document or annotate sentences out-of-context; our dataset annotates entire documents in a much finer-grained way. In an experimental study, we model the annotations of our dataset using state-of-the-art neural models. In our few-shot scenario, we find that for identifying the MITRE ATT&CK concepts that are mentioned explicitly or implicitly in a text, concept descriptions from MITRE ATT&CK are an effective source for training data augmentation.
Recommendations by Concise User Profiles from Review Text
Nov 02, 2023Recommender systems are most successful for popular items and users with ample interactions (likes, ratings etc.). This work addresses the difficult and underexplored case of supporting users who have very sparse interactions but post informative review texts. Our experimental studies address two book communities with these characteristics. We design a framework with Transformer-based representation learning, covering user-item interactions, item content, and user-provided reviews. To overcome interaction sparseness, we devise techniques for selecting the most informative cues to construct concise user profiles. Comprehensive experiments, with datasets from Amazon and Goodreads, show that judicious selection of text snippets achieves the best performance, even in comparison to ChatGPT-generated user profiles.
You Get What You Chat: Using Conversations to Personalize Search-based Recommendations
Sep 10, 2021
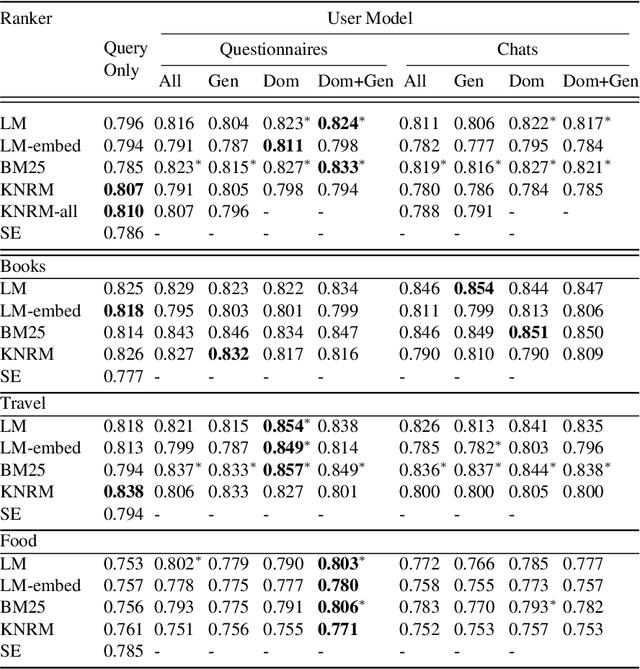


Prior work on personalized recommendations has focused on exploiting explicit signals from user-specific queries, clicks, likes, and ratings. This paper investigates tapping into a different source of implicit signals of interests and tastes: online chats between users. The paper develops an expressive model and effective methods for personalizing search-based entity recommendations. User models derived from chats augment different methods for re-ranking entity answers for medium-grained queries. The paper presents specific techniques to enhance the user models by capturing domain-specific vocabularies and by entity-based expansion. Experiments are based on a collection of online chats from a controlled user study covering three domains: books, travel, food. We evaluate different configurations and compare chat-based user models against concise user profiles from questionnaires. Overall, these two variants perform on par in terms of NCDG@20, but each has advantages in certain domains.
Personalized Entity Search by Sparse and Scrutable User Profiles
Sep 10, 2021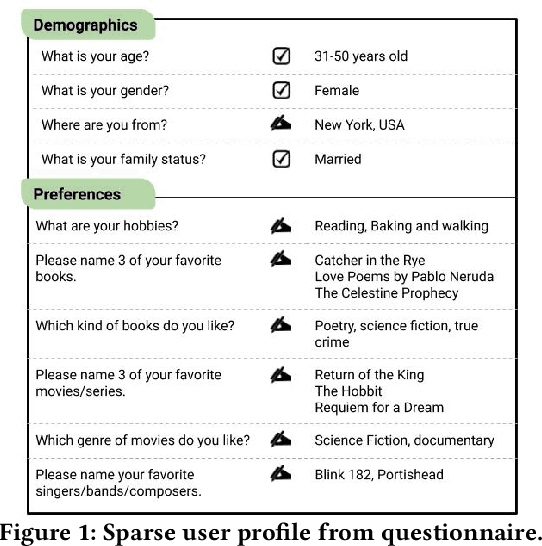
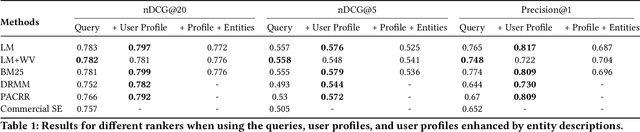
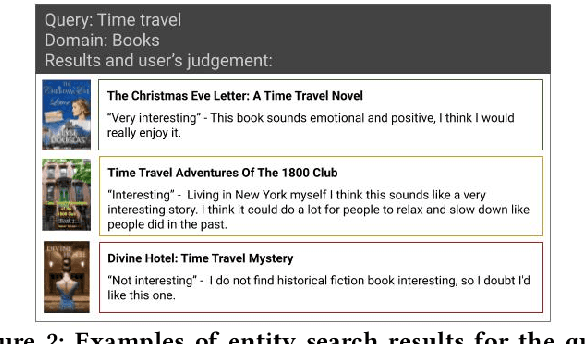
Prior work on personalizing web search results has focused on considering query-and-click logs to capture users individual interests. For product search, extensive user histories about purchases and ratings have been exploited. However, for general entity search, such as for books on specific topics or travel destinations with certain features, personalization is largely underexplored. In this paper, we address personalization of book search, as an exemplary case of entity search, by exploiting sparse user profiles obtained through online questionnaires. We devise and compare a variety of re-ranking methods based on language models or neural learning. Our experiments show that even very sparse information about individuals can enhance the effectiveness of the search results.