 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe SPECIAL-K Personal Data Processing Transparency and Compliance Platform
Jan 26, 2020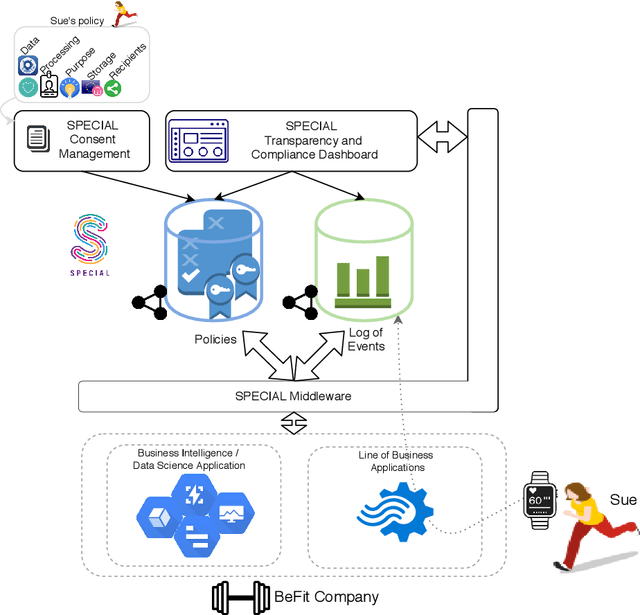
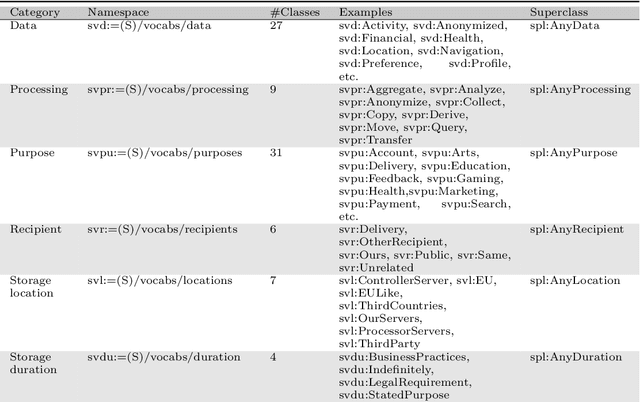
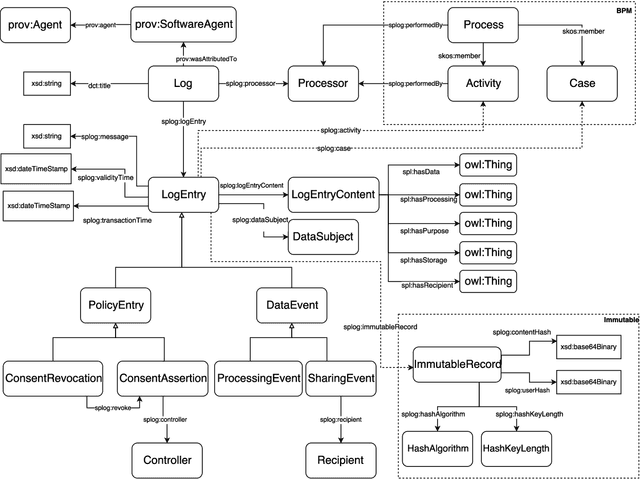

The European General Data Protection Regulation (GDPR) brings new challenges for companies, who must provide transparency with respect to personal data processing and sharing within and between organisations. Additionally companies need to demonstrate that their systems and business processes comply with usage constraints specified by data subjects. This paper first presents the Linked Data ontologies and vocabularies developed within the SPECIAL EU H2020 project, which can be used to represent data usage policies and data processing and sharing events, including the consent provided by the data subject and subsequent changes to or revocation of said consent. Following on from this, we propose a concrete transparency and compliance architecture, referred to as SPECIAL-K, that can automatically verify that data processing and sharing complies with the relevant usage control policies. Our evaluation, based on a new transparency and compliance benchmark, shows the efficiency and scalability of the system with increasing number of events and users, covering a wide range of real-world streaming and batch processing scenarios.
An Empirical Study of Real-World SPARQL Queries
Mar 25, 2011
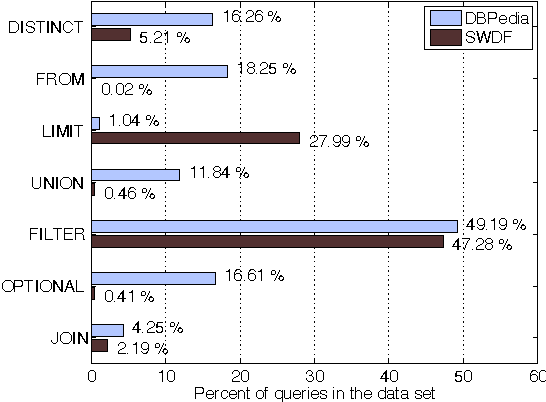
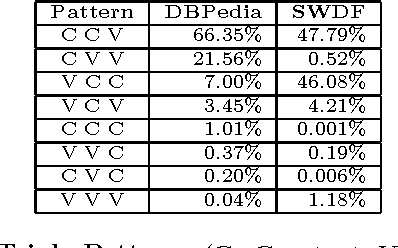
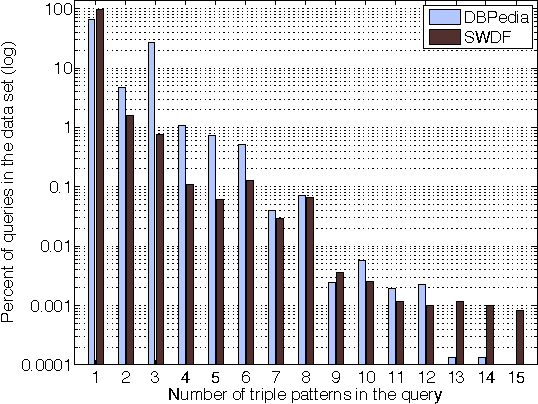
Understanding how users tailor their SPARQL queries is crucial when designing query evaluation engines or fine-tuning RDF stores with performance in mind. In this paper we analyze 3 million real-world SPARQL queries extracted from logs of the DBPedia and SWDF public endpoints. We aim at finding which are the most used language elements both from syntactical and structural perspectives, paying special attention to triple patterns and joins, since they are indeed some of the most expensive SPARQL operations at evaluation phase. We have determined that most of the queries are simple and include few triple patterns and joins, being Subject-Subject, Subject-Object and Object-Object the most common join types. The graph patterns are usually star-shaped and despite triple pattern chains exist, they are generally short.