 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Web and Creative AI -- A Technical Report from ISWS 2023
Jan 30, 2025



The International Semantic Web Research School (ISWS) is a week-long intensive program designed to immerse participants in the field. This document reports a collaborative effort performed by ten teams of students, each guided by a senior researcher as their mentor, attending ISWS 2023. Each team provided a different perspective to the topic of creative AI, substantiated by a set of research questions as the main subject of their investigation. The 2023 edition of ISWS focuses on the intersection of Semantic Web technologies and Creative AI. ISWS 2023 explored various intersections between Semantic Web technologies and creative AI. A key area of focus was the potential of LLMs as support tools for knowledge engineering. Participants also delved into the multifaceted applications of LLMs, including legal aspects of creative content production, humans in the loop, decentralised approaches to multimodal generative AI models, nanopublications and AI for personal scientific knowledge graphs, commonsense knowledge in automatic story and narrative completion, generative AI for art critique, prompt engineering, automatic music composition, commonsense prototyping and conceptual blending, and elicitation of tacit knowledge. As Large Language Models and semantic technologies continue to evolve, new exciting prospects are emerging: a future where the boundaries between creative expression and factual knowledge become increasingly permeable and porous, leading to a world of knowledge that is both informative and inspiring.
Trust, Accountability, and Autonomy in Knowledge Graph-based AI for Self-determination
Oct 31, 2023Knowledge Graphs (KGs) have emerged as fundamental platforms for powering intelligent decision-making and a wide range of Artificial Intelligence (AI) services across major corporations such as Google, Walmart, and AirBnb. KGs complement Machine Learning (ML) algorithms by providing data context and semantics, thereby enabling further inference and question-answering capabilities. The integration of KGs with neuronal learning (e.g., Large Language Models (LLMs)) is currently a topic of active research, commonly named neuro-symbolic AI. Despite the numerous benefits that can be accomplished with KG-based AI, its growing ubiquity within online services may result in the loss of self-determination for citizens as a fundamental societal issue. The more we rely on these technologies, which are often centralised, the less citizens will be able to determine their own destinies. To counter this threat, AI regulation, such as the European Union (EU) AI Act, is being proposed in certain regions. The regulation sets what technologists need to do, leading to questions concerning: How can the output of AI systems be trusted? What is needed to ensure that the data fuelling and the inner workings of these artefacts are transparent? How can AI be made accountable for its decision-making? This paper conceptualises the foundational topics and research pillars to support KG-based AI for self-determination. Drawing upon this conceptual framework, challenges and opportunities for citizen self-determination are illustrated and analysed in a real-world scenario. As a result, we propose a research agenda aimed at accomplishing the recommended objectives.
Knowledge Graphs Evolution and Preservation -- A Technical Report from ISWS 2019
Dec 22, 2020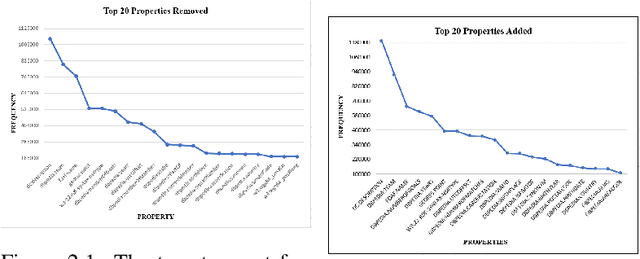
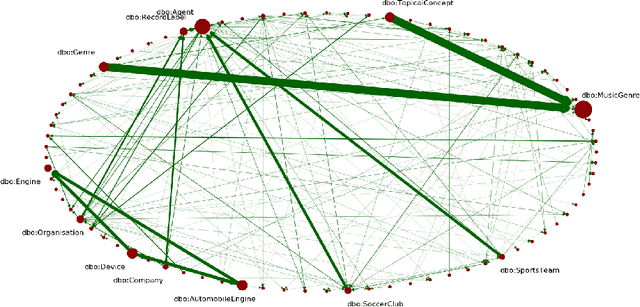

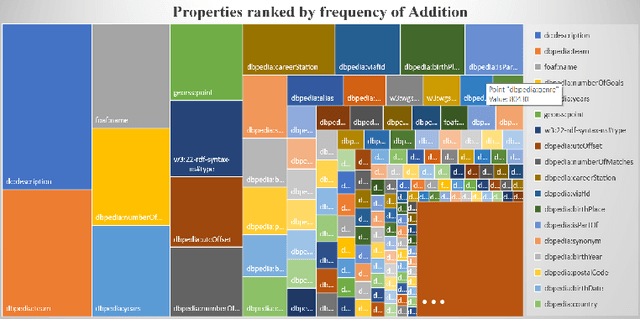
One of the grand challenges discussed during the Dagstuhl Seminar "Knowledge Graphs: New Directions for Knowledge Representation on the Semantic Web" and described in its report is that of a: "Public FAIR Knowledge Graph of Everything: We increasingly see the creation of knowledge graphs that capture information about the entirety of a class of entities. [...] This grand challenge extends this further by asking if we can create a knowledge graph of "everything" ranging from common sense concepts to location based entities. This knowledge graph should be "open to the public" in a FAIR manner democratizing this mass amount of knowledge." Although linked open data (LOD) is one knowledge graph, it is the closest realisation (and probably the only one) to a public FAIR Knowledge Graph (KG) of everything. Surely, LOD provides a unique testbed for experimenting and evaluating research hypotheses on open and FAIR KG. One of the most neglected FAIR issues about KGs is their ongoing evolution and long term preservation. We want to investigate this problem, that is to understand what preserving and supporting the evolution of KGs means and how these problems can be addressed. Clearly, the problem can be approached from different perspectives and may require the development of different approaches, including new theories, ontologies, metrics, strategies, procedures, etc. This document reports a collaborative effort performed by 9 teams of students, each guided by a senior researcher as their mentor, attending the International Semantic Web Research School (ISWS 2019). Each team provides a different perspective to the problem of knowledge graph evolution substantiated by a set of research questions as the main subject of their investigation. In addition, they provide their working definition for KG preservation and evolution.
Leveraging Textual Features for Best Answer Prediction in Community-based Question Answering
Jun 17, 2015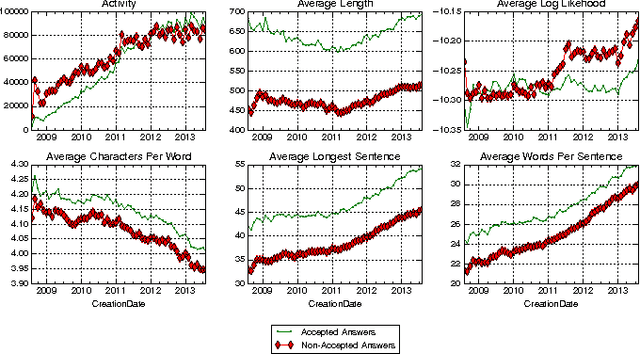
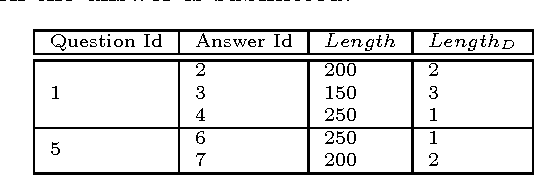
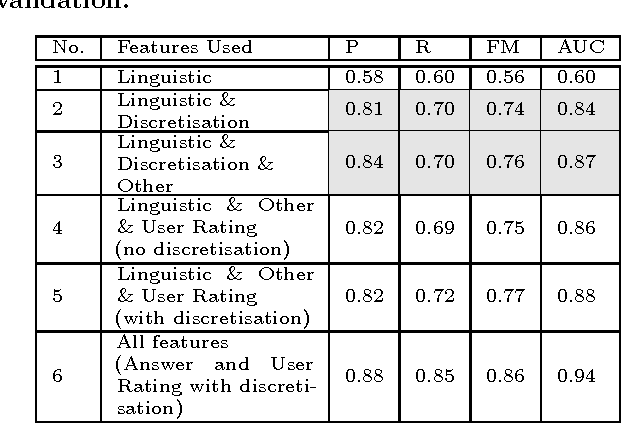
This paper addresses the problem of determining the best answer in Community-based Question Answering (CQA) websites by focussing on the content. In particular, we present a system, ACQUA [http://acqua.kmi.open.ac.uk], that can be installed onto the majority of browsers as a plugin. The service offers a seamless and accurate prediction of the answer to be accepted. Previous research on this topic relies on the exploitation of community feedback on the answers, which involves rating of either users (e.g., reputation) or answers (e.g. scores manually assigned to answers). We propose a new technique that leverages the content/textual features of answers in a novel way. Our approach delivers better results than related linguistics-based solutions and manages to match rating-based approaches. More specifically, the gain in performance is achieved by rendering the values of these features into a discretised form. We also show how our technique manages to deliver equally good results in real-time settings, as opposed to having to rely on information not always readily available, such as user ratings and answer scores. We ran an evaluation on 21 StackExchange websites covering around 4 million questions and more than 8 million answers. We obtain 84% average precision and 70% recall, which shows that our technique is robust, effective, and widely applicable.
Representing Scholarly Claims in Internet Digital Libraries: A Knowledge Modelling Approach
Aug 19, 1999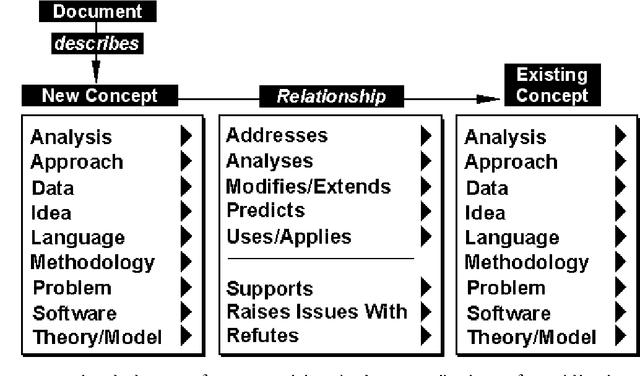
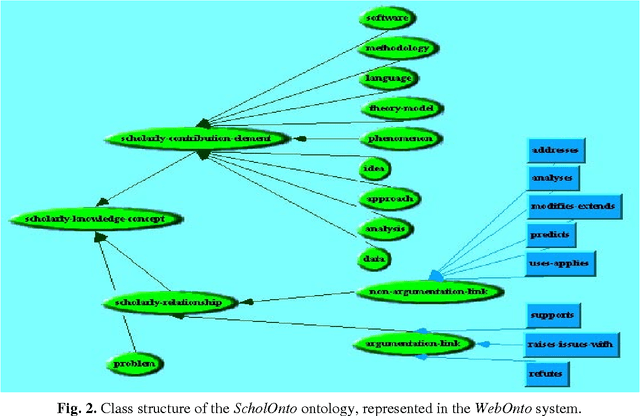
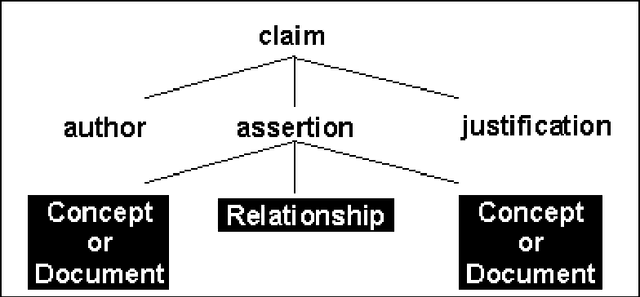
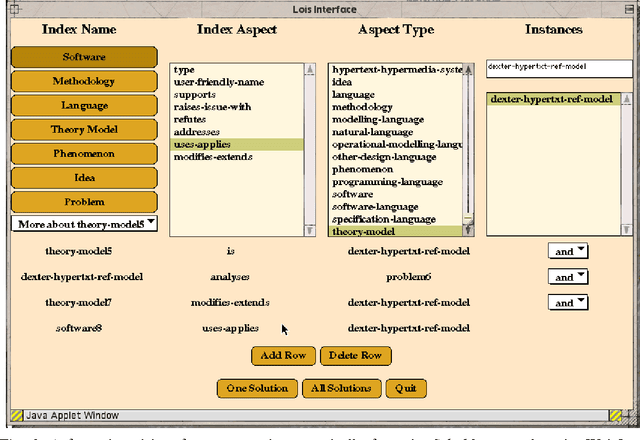
This paper is concerned with tracking and interpreting scholarly documents in distributed research communities. We argue that current approaches to document description, and current technological infrastructures particularly over the World Wide Web, provide poor support for these tasks. We describe the design of a digital library server which will enable authors to submit a summary of the contributions they claim their documents makes, and its relations to the literature. We describe a knowledge-based Web environment to support the emergence of such a community-constructed semantic hypertext, and the services it could provide to assist the interpretation of an idea or document in the context of its literature. The discussion considers in detail how the approach addresses usability issues associated with knowledge structuring environments.