 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVQ-Style: Disentangling Style and Content in Motion with Residual Quantized Representations
Feb 02, 2026Human motion data is inherently rich and complex, containing both semantic content and subtle stylistic features that are challenging to model. We propose a novel method for effective disentanglement of the style and content in human motion data to facilitate style transfer. Our approach is guided by the insight that content corresponds to coarse motion attributes while style captures the finer, expressive details. To model this hierarchy, we employ Residual Vector Quantized Variational Autoencoders (RVQ-VAEs) to learn a coarse-to-fine representation of motion. We further enhance the disentanglement by integrating contrastive learning and a novel information leakage loss with codebook learning to organize the content and the style across different codebooks. We harness this disentangled representation using our simple and effective inference-time technique Quantized Code Swapping, which enables motion style transfer without requiring any fine-tuning for unseen styles. Our framework demonstrates strong versatility across multiple inference applications, including style transfer, style removal, and motion blending.
Generalized Pose Space Embeddings for Training In-the-Wild using Anaylis-by-Synthesis
Nov 13, 2024



Modern pose estimation models are trained on large, manually-labelled datasets which are costly and may not cover the full extent of human poses and appearances in the real world. With advances in neural rendering, analysis-by-synthesis and the ability to not only predict, but also render the pose, is becoming an appealing framework, which could alleviate the need for large scale manual labelling efforts. While recent work have shown the feasibility of this approach, the predictions admit many flips due to a simplistic intermediate skeleton representation, resulting in low precision and inhibiting the acquisition of any downstream knowledge such as three-dimensional positioning. We solve this problem with a more expressive intermediate skeleton representation capable of capturing the semantics of the pose (left and right), which significantly reduces flips. To successfully train this new representation, we extend the analysis-by-synthesis framework with a training protocol based on synthetic data. We show that our representation results in less flips and more accurate predictions. Our approach outperforms previous models trained with analysis-by-synthesis on standard benchmarks.
LiteVAE: Lightweight and Efficient Variational Autoencoders for Latent Diffusion Models
May 23, 2024Advances in latent diffusion models (LDMs) have revolutionized high-resolution image generation, but the design space of the autoencoder that is central to these systems remains underexplored. In this paper, we introduce LiteVAE, a family of autoencoders for LDMs that leverage the 2D discrete wavelet transform to enhance scalability and computational efficiency over standard variational autoencoders (VAEs) with no sacrifice in output quality. We also investigate the training methodologies and the decoder architecture of LiteVAE and propose several enhancements that improve the training dynamics and reconstruction quality. Our base LiteVAE model matches the quality of the established VAEs in current LDMs with a six-fold reduction in encoder parameters, leading to faster training and lower GPU memory requirements, while our larger model outperforms VAEs of comparable complexity across all evaluated metrics (rFID, LPIPS, PSNR, and SSIM).
CADS: Unleashing the Diversity of Diffusion Models through Condition-Annealed Sampling
Oct 26, 2023While conditional diffusion models are known to have good coverage of the data distribution, they still face limitations in output diversity, particularly when sampled with a high classifier-free guidance scale for optimal image quality or when trained on small datasets. We attribute this problem to the role of the conditioning signal in inference and offer an improved sampling strategy for diffusion models that can increase generation diversity, especially at high guidance scales, with minimal loss of sample quality. Our sampling strategy anneals the conditioning signal by adding scheduled, monotonically decreasing Gaussian noise to the conditioning vector during inference to balance diversity and condition alignment. Our Condition-Annealed Diffusion Sampler (CADS) can be used with any pretrained model and sampling algorithm, and we show that it boosts the diversity of diffusion models in various conditional generation tasks. Further, using an existing pretrained diffusion model, CADS achieves a new state-of-the-art FID of 1.70 and 2.31 for class-conditional ImageNet generation at 256$\times$256 and 512$\times$512 respectively.
Domain Authoring Assistant for Intelligent Virtual Agents
Apr 05, 2019

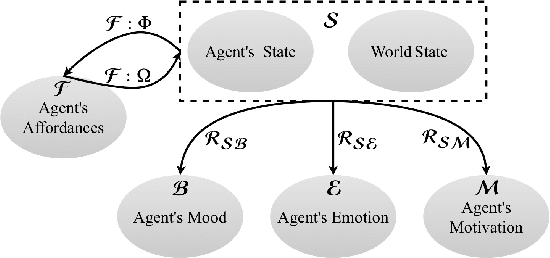

Developing intelligent virtual characters has attracted a lot of attention in the recent years. The process of creating such characters often involves a team of creative authors who describe different aspects of the characters in natural language, and planning experts that translate this description into a planning domain. This can be quite challenging as the team of creative authors should diligently define every aspect of the character especially if it contains complex human-like behavior. Also a team of engineers has to manually translate the natural language description of a character's personality into the planning domain knowledge. This can be extremely time and resource demanding and can be an obstacle to author's creativity. The goal of this paper is to introduce an authoring assistant tool to automate the process of domain generation from natural language description of virtual characters, thus bridging between the creative authoring team and the planning domain experts. Moreover, the proposed tool also identifies possible missing information in the domain description and iteratively makes suggestions to the author.