 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast and Effective On-policy Distillation from Reasoning Prefixes
Feb 16, 2026On-policy distillation (OPD), which samples trajectories from the student model and supervises them with a teacher at the token level, avoids relying solely on verifiable terminal rewards and can yield better generalization than off-policy distillation. However, OPD requires expensive on-the-fly sampling of the student policy during training, which substantially increases training cost, especially for long responses. Our initial analysis shows that, during OPD, training signals are often concentrated in the prefix of each output, and that even a short teacher-generated prefix can significantly help the student produce the correct answer. Motivated by these observations, we propose a simple yet effective modification of OPD: we apply the distillation objective only to prefixes of student-generated outputs and terminate each sampling early during distillation. Experiments on a suite of AI-for-Math and out-of-domain benchmarks show that on-policy prefix distillation matches the performance of full OPD while reducing training FLOP by 2x-47x.
Health-SCORE: Towards Scalable Rubrics for Improving Health-LLMs
Jan 26, 2026Rubrics are essential for evaluating open-ended LLM responses, especially in safety-critical domains such as healthcare. However, creating high-quality and domain-specific rubrics typically requires significant human expertise time and development cost, making rubric-based evaluation and training difficult to scale. In this work, we introduce Health-SCORE, a generalizable and scalable rubric-based training and evaluation framework that substantially reduces rubric development costs without sacrificing performance. We show that Health-SCORE provides two practical benefits beyond standalone evaluation: it can be used as a structured reward signal to guide reinforcement learning with safety-aware supervision, and it can be incorporated directly into prompts to improve response quality through in-context learning. Across open-ended healthcare tasks, Health-SCORE achieves evaluation quality comparable to human-created rubrics while significantly lowering development effort, making rubric-based evaluation and training more scalable.
MultiModal Bias: Introducing a Framework for Stereotypical Bias Assessment beyond Gender and Race in Vision Language Models
Mar 16, 2023



Recent breakthroughs in self supervised training have led to a new class of pretrained vision language models. While there have been investigations of bias in multimodal models, they have mostly focused on gender and racial bias, giving much less attention to other relevant groups, such as minorities with regard to religion, nationality, sexual orientation, or disabilities. This is mainly due to lack of suitable benchmarks for such groups. We seek to address this gap by providing a visual and textual bias benchmark called MMBias, consisting of around 3,800 images and phrases covering 14 population subgroups. We utilize this dataset to assess bias in several prominent self supervised multimodal models, including CLIP, ALBEF, and ViLT. Our results show that these models demonstrate meaningful bias favoring certain groups. Finally, we introduce a debiasing method designed specifically for such large pre-trained models that can be applied as a post-processing step to mitigate bias, while preserving the remaining accuracy of the model.
Scalable Object-Oriented Sequential Generative Models
Oct 06, 2019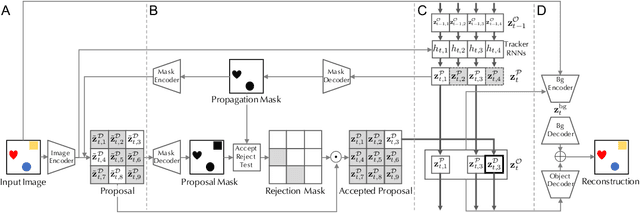
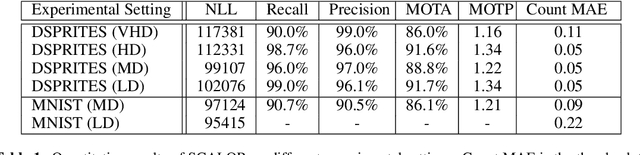


The main limitation of previous approaches to unsupervised sequential object-oriented representation learning is in scalability. Most of the previous models have been shown to work only on scenes with a few objects. In this paper, we propose SCALOR, a generative model for SCALable sequential Object-oriented Representation. With the proposed spatially-parallel attention and proposal-rejection mechanism, SCALOR can deal with orders of magnitude more number of objects compared to the current state-of-the-art models. Besides, we introduce the background model so that SCALOR can model complex background along with many foreground objects. We demonstrate that SCALOR can deal with crowded scenes containing nearly a hundred objects while modeling complex background as well. Importantly, SCALOR is the first unsupervised model demonstrating its working in natural scenes containing several tens of moving objects.
Domain Authoring Assistant for Intelligent Virtual Agents
Apr 05, 2019

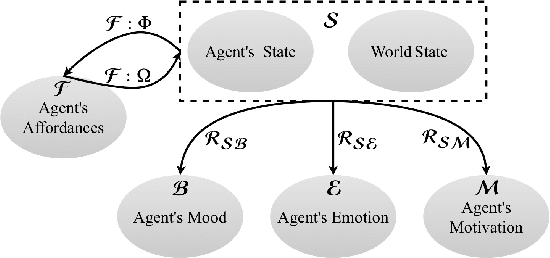

Developing intelligent virtual characters has attracted a lot of attention in the recent years. The process of creating such characters often involves a team of creative authors who describe different aspects of the characters in natural language, and planning experts that translate this description into a planning domain. This can be quite challenging as the team of creative authors should diligently define every aspect of the character especially if it contains complex human-like behavior. Also a team of engineers has to manually translate the natural language description of a character's personality into the planning domain knowledge. This can be extremely time and resource demanding and can be an obstacle to author's creativity. The goal of this paper is to introduce an authoring assistant tool to automate the process of domain generation from natural language description of virtual characters, thus bridging between the creative authoring team and the planning domain experts. Moreover, the proposed tool also identifies possible missing information in the domain description and iteratively makes suggestions to the author.
Topic Spotting using Hierarchical Networks with Self Attention
Apr 04, 2019



Success of deep learning techniques have renewed the interest in development of dialogue systems. However, current systems struggle to have consistent long term conversations with the users and fail to build rapport. Topic spotting, the task of automatically inferring the topic of a conversation, has been shown to be helpful in making a dialog system more engaging and efficient. We propose a hierarchical model with self attention for topic spotting. Experiments on the Switchboard corpus show the superior performance of our model over previously proposed techniques for topic spotting and deep models for text classification. Additionally, in contrast to offline processing of dialog, we also analyze the performance of our model in a more realistic setting i.e. in an online setting where the topic is identified in real time as the dialog progresses. Results show that our model is able to generalize even with limited information in the online setting.