Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA German Corpus for Text Similarity Detection Tasks
Mar 11, 2017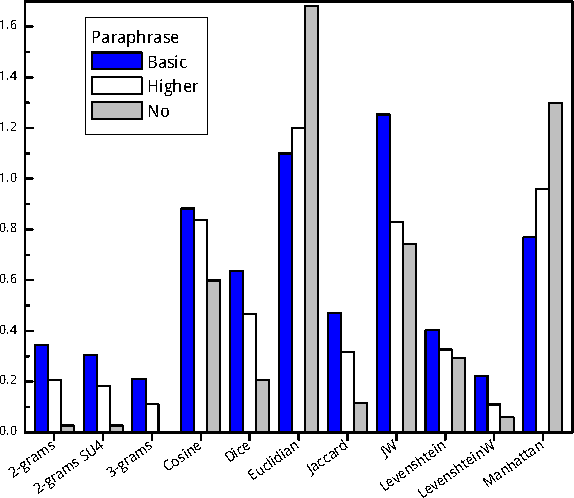
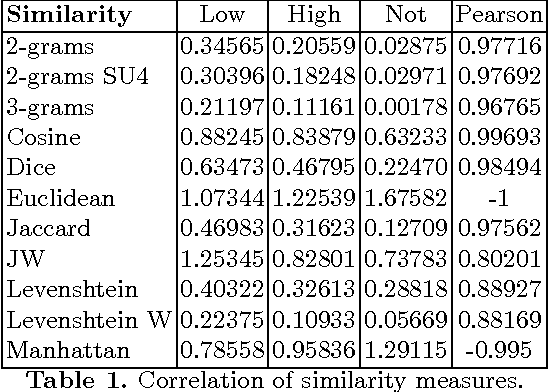
Text similarity detection aims at measuring the degree of similarity between a pair of texts. Corpora available for text similarity detection are designed to evaluate the algorithms to assess the paraphrase level among documents. In this paper we present a textual German corpus for similarity detection. The purpose of this corpus is to automatically assess the similarity between a pair of texts and to evaluate different similarity measures, both for whole documents or for individual sentences. Therefore we have calculated several simple measures on our corpus based on a library of similarity functions.
* Preprint of International Journal of Computational Linguistics and
Applications, vol. 5, no. 2, 2014, pp. 9-24
* 1 figure; 13 pages
* 1 figure; 13 pages
Via