 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Links on Wikipedia with Anchor Text Information
May 25, 2021
Wikipedia, the largest open-collaborative online encyclopedia, is a corpus of documents bound together by internal hyperlinks. These links form the building blocks of a large network whose structure contains important information on the concepts covered in this encyclopedia. The presence of a link between two articles, materialised by an anchor text in the source page pointing to the target page, can increase readers' understanding of a topic. However, the process of linking follows specific editorial rules to avoid both under-linking and over-linking. In this paper, we study the transductive and the inductive tasks of link prediction on several subsets of the English Wikipedia and identify some key challenges behind automatic linking based on anchor text information. We propose an appropriate evaluation sampling methodology and compare several algorithms. Moreover, we propose baseline models that provide a good estimation of the overall difficulty of the tasks.
Inductive Document Network Embedding with Topic-Word Attention
Jan 10, 2020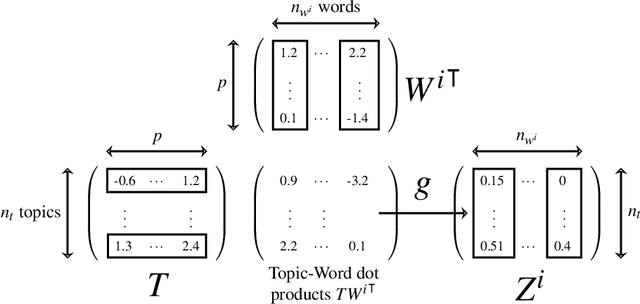



Document network embedding aims at learning representations for a structured text corpus i.e. when documents are linked to each other. Recent algorithms extend network embedding approaches by incorporating the text content associated with the nodes in their formulations. In most cases, it is hard to interpret the learned representations. Moreover, little importance is given to the generalization to new documents that are not observed within the network. In this paper, we propose an interpretable and inductive document network embedding method. We introduce a novel mechanism, the Topic-Word Attention (TWA), that generates document representations based on the interplay between word and topic representations. We train these word and topic vectors through our general model, Inductive Document Network Embedding (IDNE), by leveraging the connections in the document network. Quantitative evaluations show that our approach achieves state-of-the-art performance on various networks and we qualitatively show that our model produces meaningful and interpretable representations of the words, topics and documents.
Link Prediction with Mutual Attention for Text-Attributed Networks
Mar 20, 2019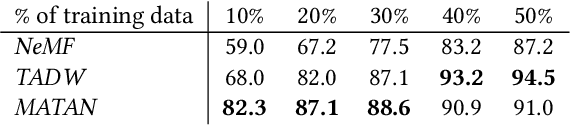

In this extended abstract, we present an algorithm that learns a similarity measure between documents from the network topology of a structured corpus. We leverage the Scaled Dot-Product Attention, a recently proposed attention mechanism, to design a mutual attention mechanism between pairs of documents. To train its parameters, we use the network links as supervision. We provide preliminary experiment results with a citation dataset on two prediction tasks, demonstrating the capacity of our model to learn a meaningful textual similarity.
Representation Learning for Recommender Systems with Application to the Scientific Literature
Feb 28, 2019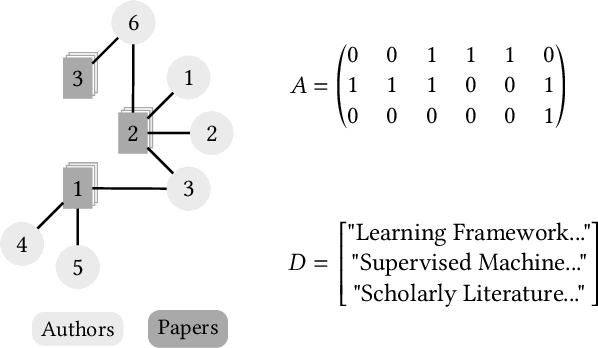



The scientific literature is a large information network linking various actors (laboratories, companies, institutions, etc.). The vast amount of data generated by this network constitutes a dynamic heterogeneous attributed network (HAN), in which new information is constantly produced and from which it is increasingly difficult to extract content of interest. In this article, I present my first thesis works in partnership with an industrial company, Digital Scientific Research Technology. This later offers a scientific watch tool, Peerus, addressing various issues, such as the real time recommendation of newly published papers or the search for active experts to start new collaborations. To tackle this diversity of applications, a common approach consists in learning representations of the nodes and attributes of this HAN and use them as features for a variety of recommendation tasks. However, most works on attributed network embedding pay too little attention to textual attributes and do not fully take advantage of recent natural language processing techniques. Moreover, proposed methods that jointly learn node and document representations do not provide a way to effectively infer representations for new documents for which network information is missing, which happens to be crucial in real time recommender systems. Finally, the interplay between textual and graph data in text-attributed heterogeneous networks remains an open research direction.
Global Vectors for Node Representations
Feb 28, 2019
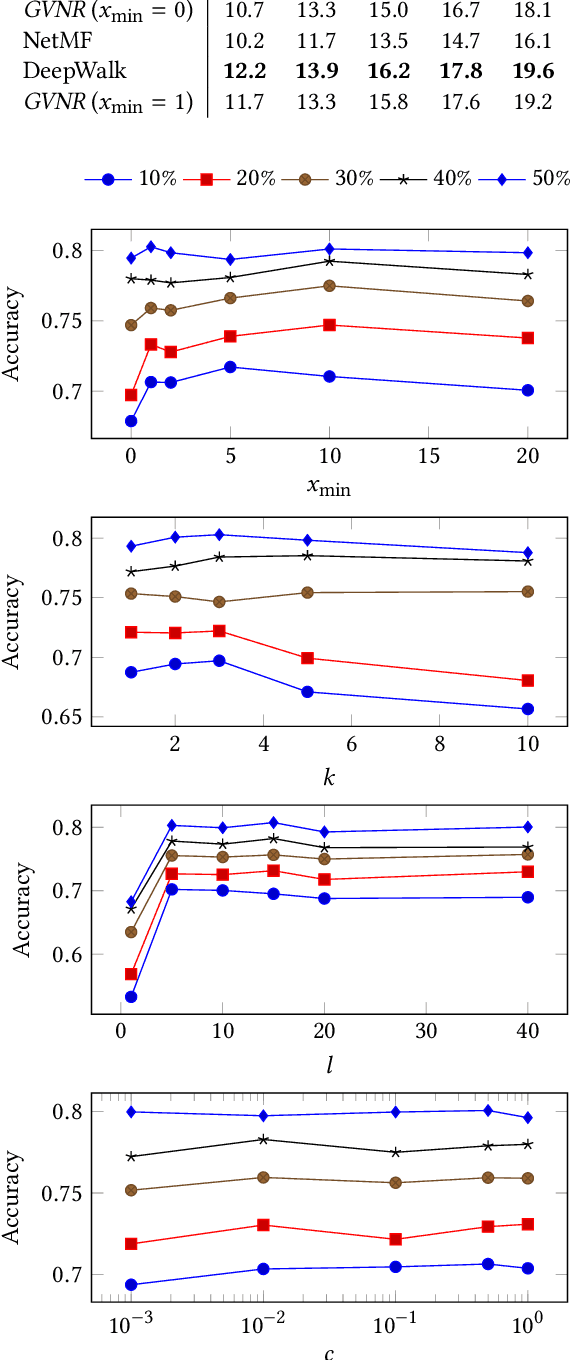
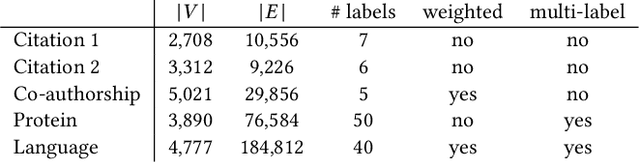

Most network embedding algorithms consist in measuring co-occurrences of nodes via random walks then learning the embeddings using Skip-Gram with Negative Sampling. While it has proven to be a relevant choice, there are alternatives, such as GloVe, which has not been investigated yet for network embedding. Even though SGNS better handles non co-occurrence than GloVe, it has a worse time-complexity. In this paper, we propose a matrix factorization approach for network embedding, inspired by GloVe, that better handles non co-occurrence with a competitive time-complexity. We also show how to extend this model to deal with networks where nodes are documents, by simultaneously learning word, node and document representations. Quantitative evaluations show that our model achieves state-of-the-art performance, while not being so sensitive to the choice of hyper-parameters. Qualitatively speaking, we show how our model helps exploring a network of documents by generating complementary network-oriented and content-oriented keywords.