 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnchor Prediction: A Topic Modeling Approach
Jun 01, 2022
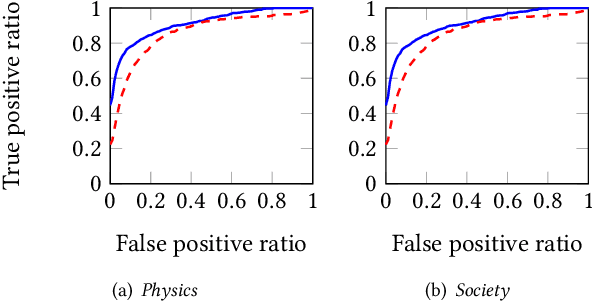
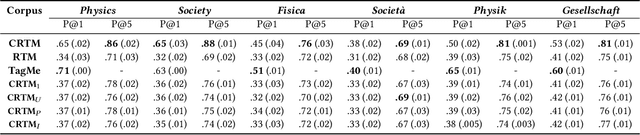

Networks of documents connected by hyperlinks, such as Wikipedia, are ubiquitous. Hyperlinks are inserted by the authors to enrich the text and facilitate the navigation through the network. However, authors tend to insert only a fraction of the relevant hyperlinks, mainly because this is a time consuming task. In this paper we address an annotation, which we refer to as anchor prediction. Even though it is conceptually close to link prediction or entity linking, it is a different task that require developing a specific method to solve it. Given a source document and a target document, this task consists in automatically identifying anchors in the source document, i.e words or terms that should carry a hyperlink pointing towards the target document. We propose a contextualized relational topic model, CRTM, that models directed links between documents as a function of the local context of the anchor in the source document and the whole content of the target document. The model can be used to predict anchors in a source document, given the target document, without relying on a dictionary of previously seen mention or title, nor any external knowledge graph. Authors can benefit from CRTM, by letting it automatically suggest hyperlinks, given a new document and the set of target document to connect to. It can also benefit to readers, by dynamically inserting hyperlinks between the documents they're reading. Experiments conducted on several Wikipedia corpora (in English, Italian and German) highlight the practical usefulness of anchor prediction and demonstrate the relevancy of our approach.
Document Network Projection in Pretrained Word Embedding Space
Jan 16, 2020
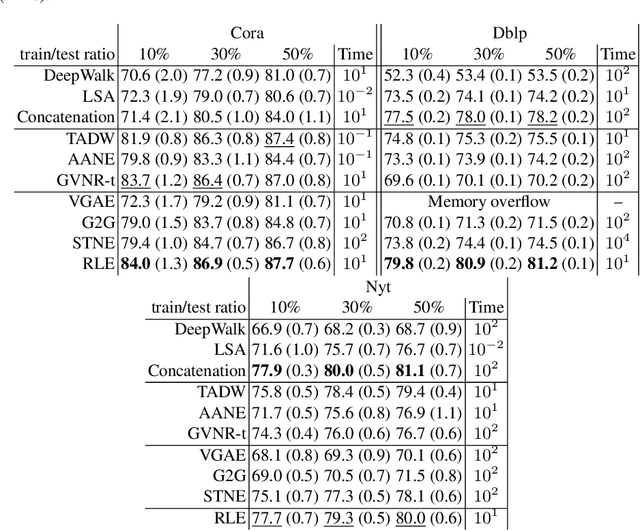
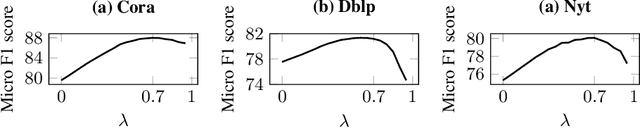

We present Regularized Linear Embedding (RLE), a novel method that projects a collection of linked documents (e.g. citation network) into a pretrained word embedding space. In addition to the textual content, we leverage a matrix of pairwise similarities providing complementary information (e.g., the network proximity of two documents in a citation graph). We first build a simple word vector average for each document, and we use the similarities to alter this average representation. The document representations can help to solve many information retrieval tasks, such as recommendation, classification and clustering. We demonstrate that our approach outperforms or matches existing document network embedding methods on node classification and link prediction tasks. Furthermore, we show that it helps identifying relevant keywords to describe document classes.
Inductive Document Network Embedding with Topic-Word Attention
Jan 10, 2020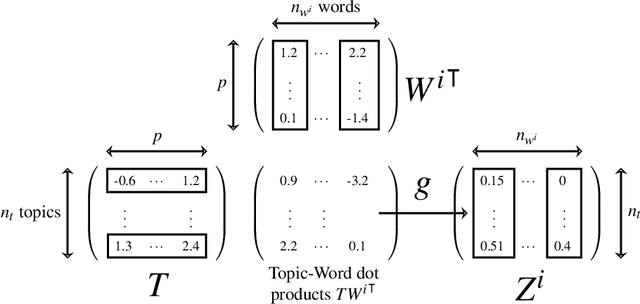



Document network embedding aims at learning representations for a structured text corpus i.e. when documents are linked to each other. Recent algorithms extend network embedding approaches by incorporating the text content associated with the nodes in their formulations. In most cases, it is hard to interpret the learned representations. Moreover, little importance is given to the generalization to new documents that are not observed within the network. In this paper, we propose an interpretable and inductive document network embedding method. We introduce a novel mechanism, the Topic-Word Attention (TWA), that generates document representations based on the interplay between word and topic representations. We train these word and topic vectors through our general model, Inductive Document Network Embedding (IDNE), by leveraging the connections in the document network. Quantitative evaluations show that our approach achieves state-of-the-art performance on various networks and we qualitatively show that our model produces meaningful and interpretable representations of the words, topics and documents.
Document Network Embedding: Coping for Missing Content and Missing Links
Dec 06, 2019
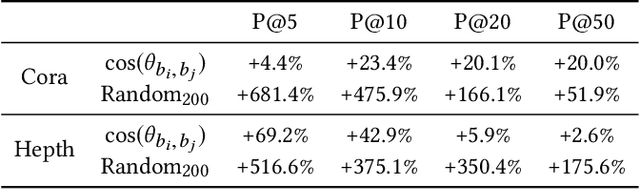
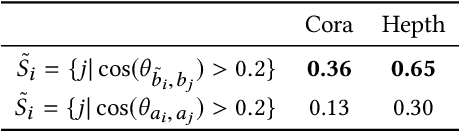
Searching through networks of documents is an important task. A promising path to improve the performance of information retrieval systems in this context is to leverage dense node and content representations learned with embedding techniques. However, these techniques cannot learn representations for documents that are either isolated or whose content is missing. To tackle this issue, assuming that the topology of the network and the content of the documents correlate, we propose to estimate the missing node representations from the available content representations, and conversely. Inspired by recent advances in machine translation, we detail in this paper how to learn a linear transformation from a set of aligned content and node representations. The projection matrix is efficiently calculated in terms of the singular value decomposition. The usefulness of the proposed method is highlighted by the improved ability to predict the neighborhood of nodes whose links are unobserved based on the projected content representations, and to retrieve similar documents when content is missing, based on the projected node representations.
Link Prediction with Mutual Attention for Text-Attributed Networks
Mar 20, 2019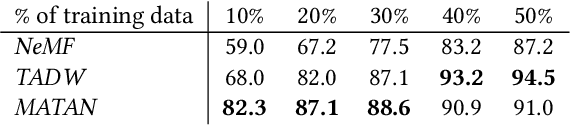

In this extended abstract, we present an algorithm that learns a similarity measure between documents from the network topology of a structured corpus. We leverage the Scaled Dot-Product Attention, a recently proposed attention mechanism, to design a mutual attention mechanism between pairs of documents. To train its parameters, we use the network links as supervision. We provide preliminary experiment results with a citation dataset on two prediction tasks, demonstrating the capacity of our model to learn a meaningful textual similarity.
Global Vectors for Node Representations
Feb 28, 2019
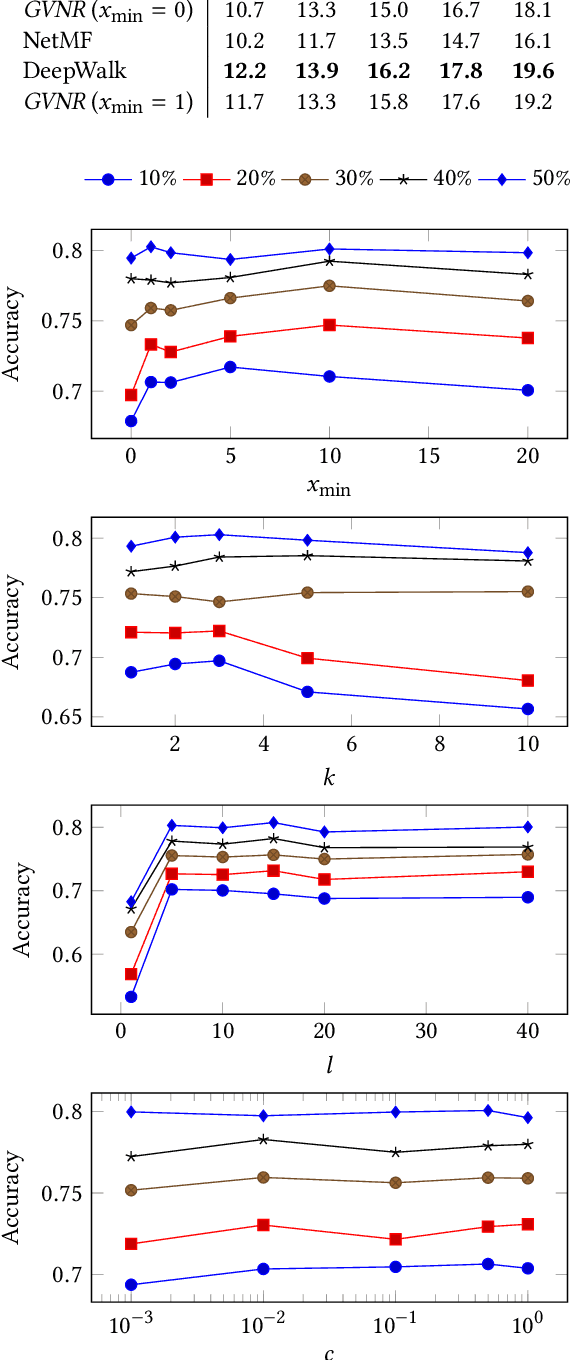
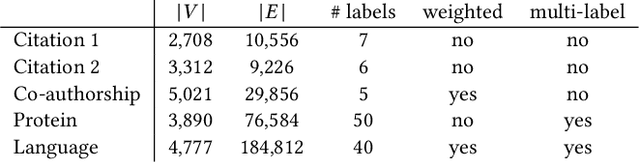

Most network embedding algorithms consist in measuring co-occurrences of nodes via random walks then learning the embeddings using Skip-Gram with Negative Sampling. While it has proven to be a relevant choice, there are alternatives, such as GloVe, which has not been investigated yet for network embedding. Even though SGNS better handles non co-occurrence than GloVe, it has a worse time-complexity. In this paper, we propose a matrix factorization approach for network embedding, inspired by GloVe, that better handles non co-occurrence with a competitive time-complexity. We also show how to extend this model to deal with networks where nodes are documents, by simultaneously learning word, node and document representations. Quantitative evaluations show that our model achieves state-of-the-art performance, while not being so sensitive to the choice of hyper-parameters. Qualitatively speaking, we show how our model helps exploring a network of documents by generating complementary network-oriented and content-oriented keywords.
CommentWatcher: An Open Source Web-based platform for analyzing discussions on web forums
Apr 28, 2015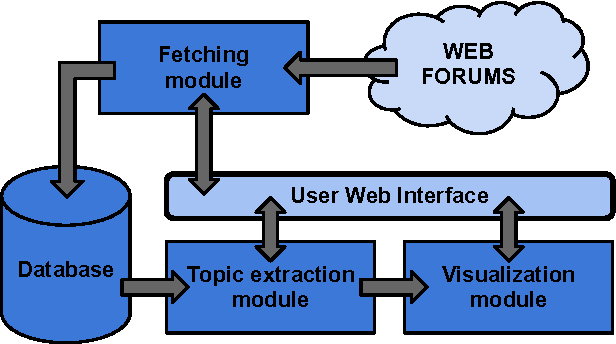



We present CommentWatcher, an open source tool aimed at analyzing discussions on web forums. Constructed as a web platform, CommentWatcher features automatic mass fetching of user posts from forum on multiple sites, extracting topics, visualizing the topics as an expression cloud and exploring their temporal evolution. The underlying social network of users is simultaneously constructed using the citation relations between users and visualized as a graph structure. Our platform addresses the issues of the diversity and dynamics of structures of webpages hosting the forums by implementing a parser architecture that is independent of the HTML structure of webpages. This allows easy on-the-fly adding of new websites. Two types of users are targeted: end users who seek to study the discussed topics and their temporal evolution, and researchers in need of establishing a forum benchmark dataset and comparing the performances of analysis tools.