 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnchor Prediction: A Topic Modeling Approach
Jun 01, 2022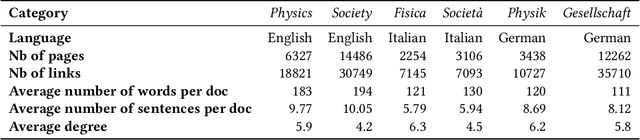
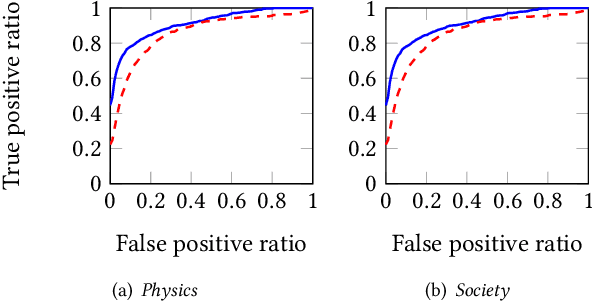
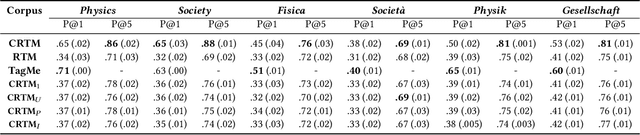

Networks of documents connected by hyperlinks, such as Wikipedia, are ubiquitous. Hyperlinks are inserted by the authors to enrich the text and facilitate the navigation through the network. However, authors tend to insert only a fraction of the relevant hyperlinks, mainly because this is a time consuming task. In this paper we address an annotation, which we refer to as anchor prediction. Even though it is conceptually close to link prediction or entity linking, it is a different task that require developing a specific method to solve it. Given a source document and a target document, this task consists in automatically identifying anchors in the source document, i.e words or terms that should carry a hyperlink pointing towards the target document. We propose a contextualized relational topic model, CRTM, that models directed links between documents as a function of the local context of the anchor in the source document and the whole content of the target document. The model can be used to predict anchors in a source document, given the target document, without relying on a dictionary of previously seen mention or title, nor any external knowledge graph. Authors can benefit from CRTM, by letting it automatically suggest hyperlinks, given a new document and the set of target document to connect to. It can also benefit to readers, by dynamically inserting hyperlinks between the documents they're reading. Experiments conducted on several Wikipedia corpora (in English, Italian and German) highlight the practical usefulness of anchor prediction and demonstrate the relevancy of our approach.
Outlier detection in multivariate functional data through a contaminated mixture model
Jun 14, 2021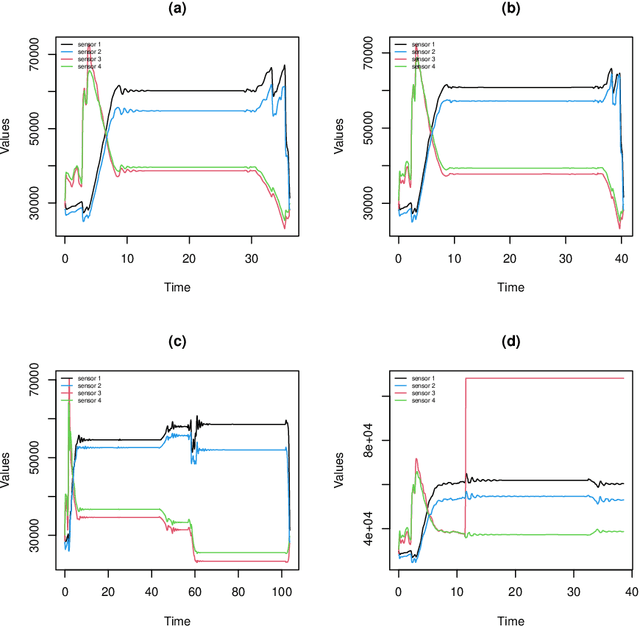

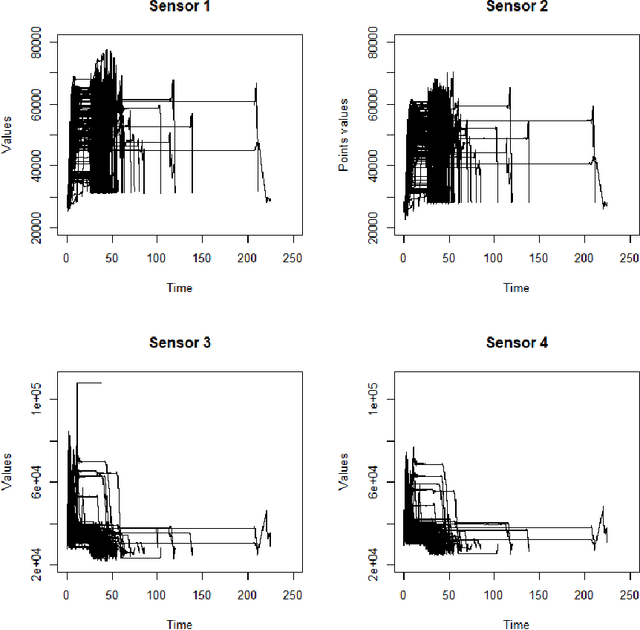

This work is motivated by an application in an industrial context, where the activity of sensors is recorded at a high frequency. The objective is to automatically detect abnormal measurement behaviour. Considering the sensor measures as functional data, we are formally interested in detecting outliers in a multivariate functional data set. Due to the heterogeneity of this data set, the proposed contaminated mixture model both clusters the multivariate functional data into homogeneous groups and detects outliers. The main advantage of this procedure over its competitors is that it does not require us to specify the proportion of outliers. Model inference is performed through an Expectation-Conditional Maximization algorithm, and the BIC criterion is used to select the number of clusters. Numerical experiments on simulated data demonstrate the high performance achieved by the inference algorithm. In particular, the proposed model outperforms competitors. Its application on the real data which motivated this study allows us to correctly detect abnormal behaviours.
Document Network Projection in Pretrained Word Embedding Space
Jan 16, 2020
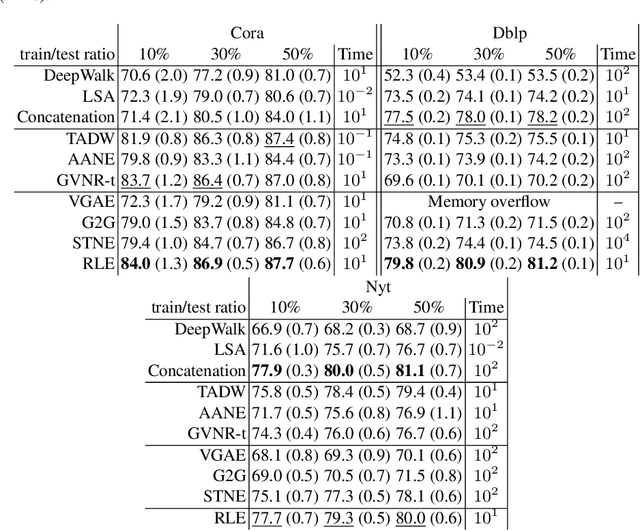
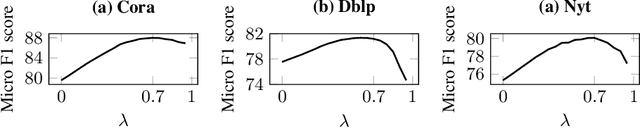

We present Regularized Linear Embedding (RLE), a novel method that projects a collection of linked documents (e.g. citation network) into a pretrained word embedding space. In addition to the textual content, we leverage a matrix of pairwise similarities providing complementary information (e.g., the network proximity of two documents in a citation graph). We first build a simple word vector average for each document, and we use the similarities to alter this average representation. The document representations can help to solve many information retrieval tasks, such as recommendation, classification and clustering. We demonstrate that our approach outperforms or matches existing document network embedding methods on node classification and link prediction tasks. Furthermore, we show that it helps identifying relevant keywords to describe document classes.
Document Network Embedding: Coping for Missing Content and Missing Links
Dec 06, 2019
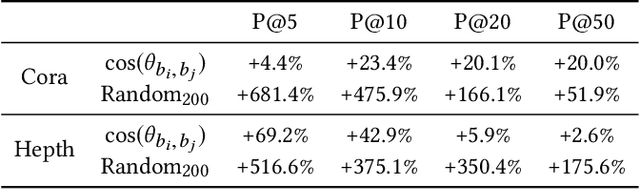
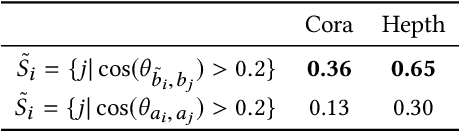
Searching through networks of documents is an important task. A promising path to improve the performance of information retrieval systems in this context is to leverage dense node and content representations learned with embedding techniques. However, these techniques cannot learn representations for documents that are either isolated or whose content is missing. To tackle this issue, assuming that the topology of the network and the content of the documents correlate, we propose to estimate the missing node representations from the available content representations, and conversely. Inspired by recent advances in machine translation, we detail in this paper how to learn a linear transformation from a set of aligned content and node representations. The projection matrix is efficiently calculated in terms of the singular value decomposition. The usefulness of the proposed method is highlighted by the improved ability to predict the neighborhood of nodes whose links are unobserved based on the projected content representations, and to retrieve similar documents when content is missing, based on the projected node representations.
Opinion mining from twitter data using evolutionary multinomial mixture models
Sep 24, 2015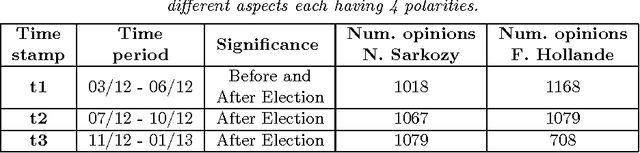

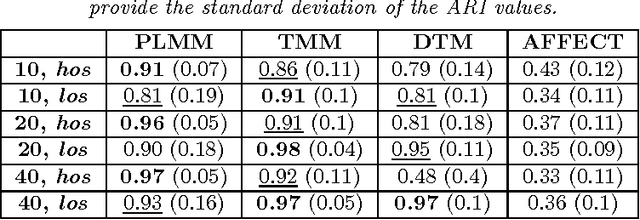
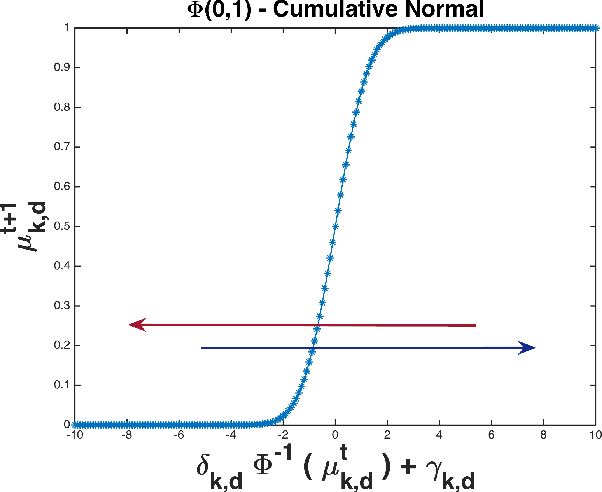
Image of an entity can be defined as a structured and dynamic representation which can be extracted from the opinions of a group of users or population. Automatic extraction of such an image has certain importance in political science and sociology related studies, e.g., when an extended inquiry from large-scale data is required. We study the images of two politically significant entities of France. These images are constructed by analyzing the opinions collected from a well known social media called Twitter. Our goal is to build a system which can be used to automatically extract the image of entities over time. In this paper, we propose a novel evolutionary clustering method based on the parametric link among Multinomial mixture models. First we propose the formulation of a generalized model that establishes parametric links among the Multinomial distributions. Afterward, we follow a model-based clustering approach to explore different parametric sub-models and select the best model. For the experiments, first we use synthetic temporal data. Next, we apply the method to analyze the annotated social media data. Results show that the proposed method is better than the state-of-the-art based on the common evaluation metrics. Additionally, our method can provide interpretation about the temporal evolution of the clusters.
Simultaneous Clustering and Model Selection for Multinomial Distribution: A Comparative Study
Sep 06, 2015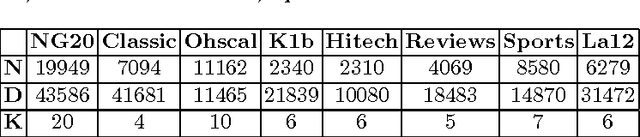
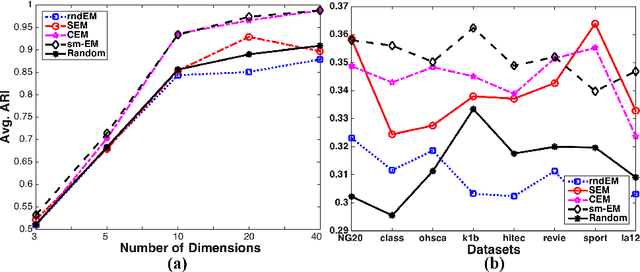
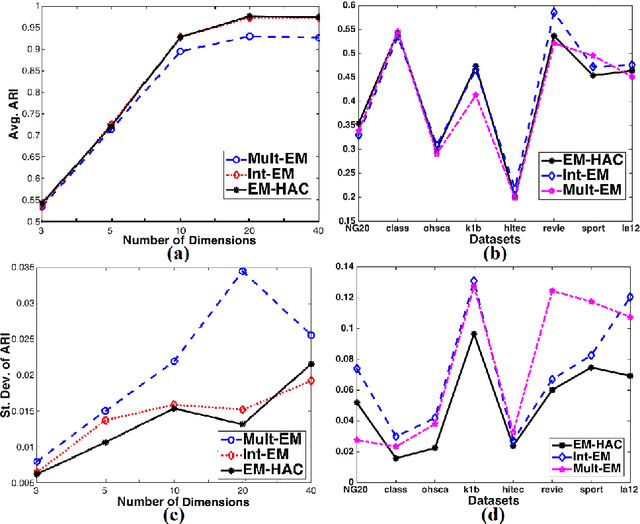

In this paper, we study different discrete data clustering methods, which use the Model-Based Clustering (MBC) framework with the Multinomial distribution. Our study comprises several relevant issues, such as initialization, model estimation and model selection. Additionally, we propose a novel MBC method by efficiently combining the partitional and hierarchical clustering techniques. We conduct experiments on both synthetic and real data and evaluate the methods using accuracy, stability and computation time. Our study identifies appropriate strategies to be used for discrete data analysis with the MBC methods. Moreover, our proposed method is very competitive w.r.t. clustering accuracy and better w.r.t. stability and computation time.