 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrelation-Based Method for Sentiment Classification
Mar 01, 2018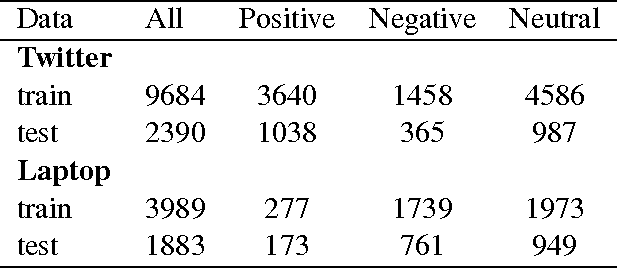

The classic supervised classification algorithms are efficient, but time-consuming, complicated and not interpretable, which makes it difficult to analyze their results that limits the possibility to improve them based on real observations. In this paper, we propose a new and a simple classifier to predict a sentiment label of a short text. This model keeps the capacity of human interpret-ability and can be extended to integrate NLP techniques in a more interpretable way. Our model is based on a correlation metric which measures the degree of association between a sentiment label and a word. Ten correlation metrics are proposed and evaluated intrinsically. And then a classifier based on each metric is proposed, evaluated and compared to the classic classification algorithms which have proved their performance in many studies. Our model outperforms these algorithms with several correlation metrics.
Graph Centrality Measures for Boosting Popularity-Based Entity Linking
Nov 30, 2017



Many Entity Linking systems use collective graph-based methods to disambiguate the entity mentions within a document. Most of them have focused on graph construction and initial weighting of the candidate entities, less attention has been devoted to compare the graph ranking algorithms. In this work, we focus on the graph-based ranking algorithms, therefore we propose to apply five centrality measures: Degree, HITS, PageRank, Betweenness and Closeness. A disambiguation graph of candidate entities is constructed for each document using the popularity method, then centrality measures are applied to choose the most relevant candidate to boost the results of entity popularity method. We investigate the effectiveness of each centrality measure on the performance across different domains and datasets. Our experiments show that a simple and fast centrality measure such as Degree centrality can outperform other more time-consuming measures.
Senti17 at SemEval-2017 Task 4: Ten Convolutional Neural Network Voters for Tweet Polarity Classification
May 04, 2017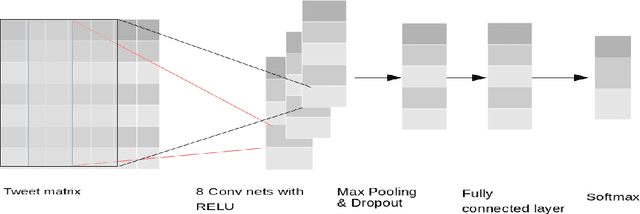
This paper presents Senti17 system which uses ten convolutional neural networks (ConvNet) to assign a sentiment label to a tweet. The network consists of a convolutional layer followed by a fully-connected layer and a Softmax on top. Ten instances of this network are initialized with the same word embeddings as inputs but with different initializations for the network weights. We combine the results of all instances by selecting the sentiment label given by the majority of the ten voters. This system is ranked fourth in SemEval-2017 Task4 over 38 systems with 67.4%
Supervised Term Weighting Metrics for Sentiment Analysis in Short Text
Oct 10, 2016
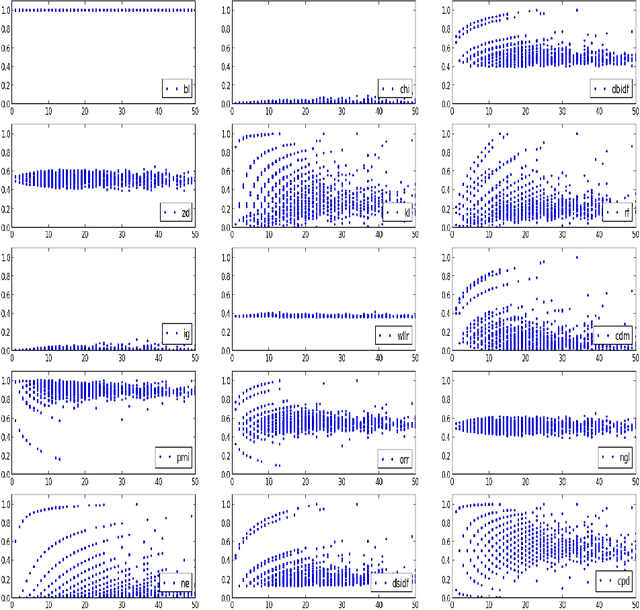
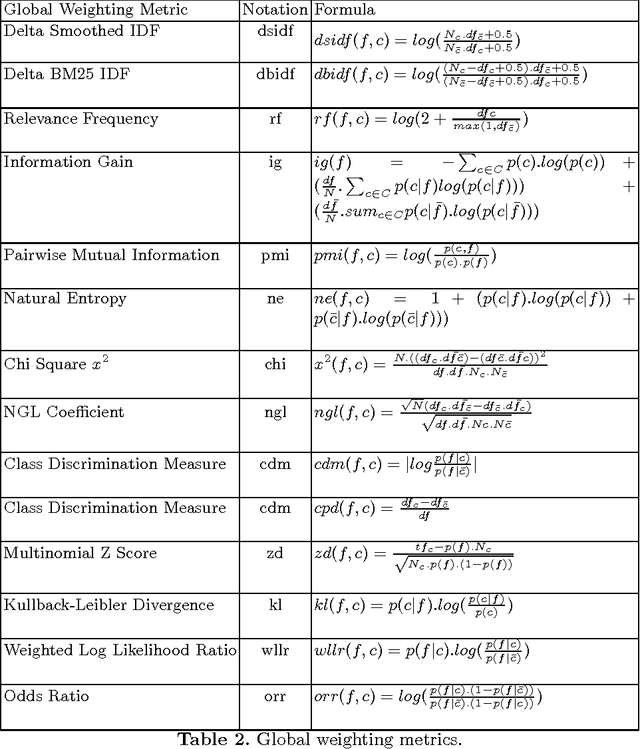
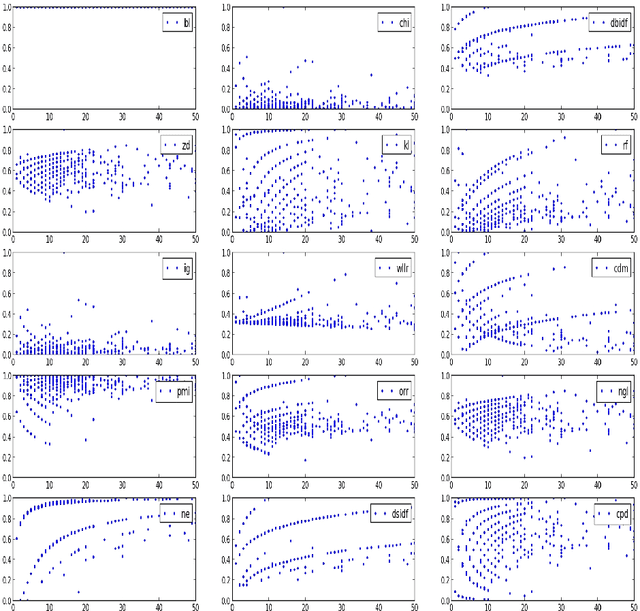
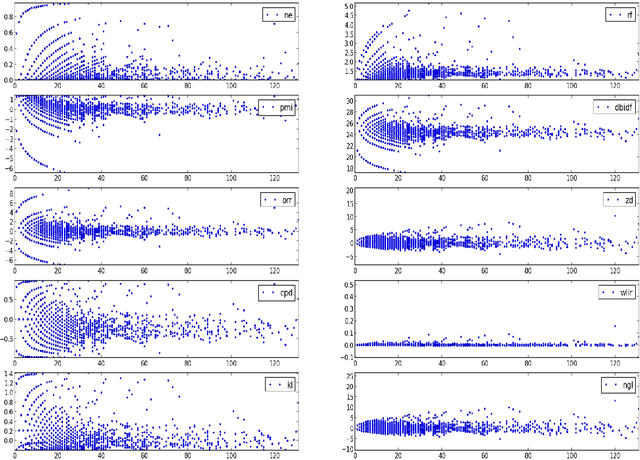
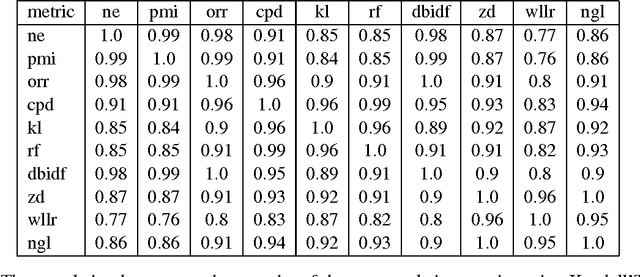
Term weighting metrics assign weights to terms in order to discriminate the important terms from the less crucial ones. Due to this characteristic, these metrics have attracted growing attention in text classification and recently in sentiment analysis. Using the weights given by such metrics could lead to more accurate document representation which may improve the performance of the classification. While previous studies have focused on proposing or comparing different weighting metrics at two-classes document level sentiment analysis, this study propose to analyse the results given by each metric in order to find out the characteristics of good and bad weighting metrics. Therefore we present an empirical study of fifteen global supervised weighting metrics with four local weighting metrics adopted from information retrieval, we also give an analysis to understand the behavior of each metric by observing and analysing how each metric distributes the terms and deduce some characteristics which may distinguish the good and bad metrics. The evaluation has been done using Support Vector Machine on three different datasets: Twitter, restaurant and laptop reviews.
Sentiment Analysis in Scholarly Book Reviews
Mar 04, 2016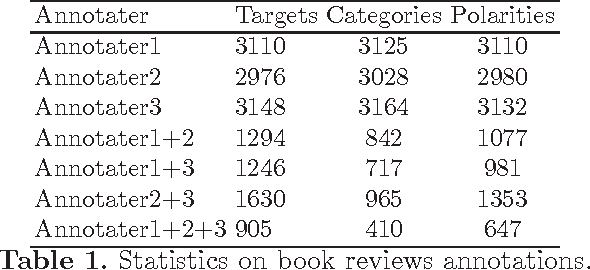
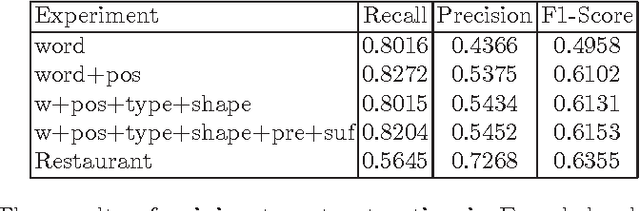
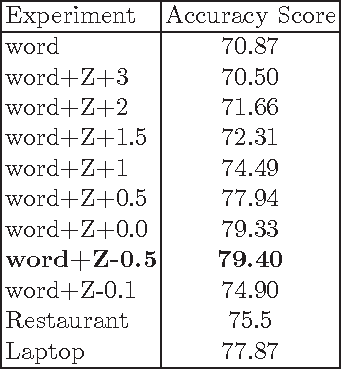
So far different studies have tackled the sentiment analysis in several domains such as restaurant and movie reviews. But, this problem has not been studied in scholarly book reviews which is different in terms of review style and size. In this paper, we propose to combine different features in order to be presented to a supervised classifiers which extract the opinion target expressions and detect their polarities in scholarly book reviews. We construct a labeled corpus for training and evaluating our methods in French book reviews. We also evaluate them on English restaurant reviews in order to measure their robustness across the domains and languages. The evaluation shows that our methods are enough robust for English restaurant reviews and French book reviews.