 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Noise to Signal: When Outliers Seed New Topics
Mar 18, 2026Outliers in dynamic topic modeling are typically treated as noise, yet we show that some can serve as early signals of emerging topics. We introduce a temporal taxonomy of news-document trajectories that defines how documents relate to topic formation over time. It distinguishes anticipatory outliers, which precede the topics they later join, from documents that either reinforce existing topics or remain isolated. By capturing these trajectories, the taxonomy links weak-signal detection with temporal topic modeling and clarifies how individual articles anticipate, initiate, or drift within evolving clusters. We implement it in a cumulative clustering setting using document embeddings from eleven state-of-the-art language models and evaluate it retrospectively on HydroNewsFr, a French news corpus on the hydrogen economy. Inter-model agreement reveals a small, high-consensus subset of anticipatory outliers, increasing confidence in these labels. Qualitative case studies further illustrate these trajectories through concrete topic developments.
From Outliers to Topics in Language Models: Anticipating Trends in News Corpora
Sep 26, 2025This paper examines how outliers, often dismissed as noise in topic modeling, can act as weak signals of emerging topics in dynamic news corpora. Using vector embeddings from state-of-the-art language models and a cumulative clustering approach, we track their evolution over time in French and English news datasets focused on corporate social responsibility and climate change. The results reveal a consistent pattern: outliers tend to evolve into coherent topics over time across both models and languages.
Embedding Style Beyond Topics: Analyzing Dispersion Effects Across Different Language Models
Jan 01, 2025



This paper analyzes how writing style affects the dispersion of embedding vectors across multiple, state-of-the-art language models. While early transformer models primarily aligned with topic modeling, this study examines the role of writing style in shaping embedding spaces. Using a literary corpus that alternates between topics and styles, we compare the sensitivity of language models across French and English. By analyzing the particular impact of style on embedding dispersion, we aim to better understand how language models process stylistic information, contributing to their overall interpretability.
Action Languages Based Actual Causality in Ethical Decision Making Contexts
May 05, 2022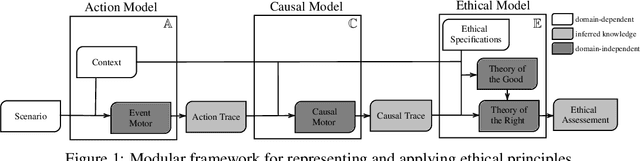
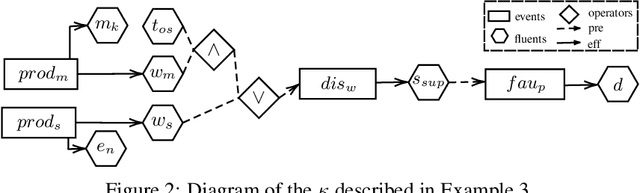

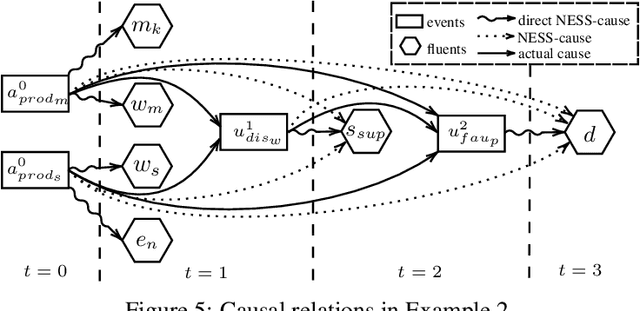
Moral responsibility is closely intermixed with causality, even if it cannot be reduced to it. Besides, rationally understanding the evolution of the physical world is inherently linked with the idea of causality. It follows that decision making applications based on automated planning, especially if they integrate references to ethical norms, have inevitably to deal with causality. Despite these considerations, much of the work in computational ethics relegates causality to the background, if not ignores it completely. This paper contribution is double. The first one is to link up two research topics$\unicode{x2014}$automated planning and causality$\unicode{x2014}$by proposing an actual causation definition suitable for action languages. This definition is a formalisation of Wright's NESS test of causation. The second is to link up computational ethics and causality by showing the importance of causality in the simulation of ethical reasoning and by enabling the domain to deal with situations that were previously out of reach thanks to the actual causation definition proposed.
Graph Centrality Measures for Boosting Popularity-Based Entity Linking
Nov 30, 2017



Many Entity Linking systems use collective graph-based methods to disambiguate the entity mentions within a document. Most of them have focused on graph construction and initial weighting of the candidate entities, less attention has been devoted to compare the graph ranking algorithms. In this work, we focus on the graph-based ranking algorithms, therefore we propose to apply five centrality measures: Degree, HITS, PageRank, Betweenness and Closeness. A disambiguation graph of candidate entities is constructed for each document using the popularity method, then centrality measures are applied to choose the most relevant candidate to boost the results of entity popularity method. We investigate the effectiveness of each centrality measure on the performance across different domains and datasets. Our experiments show that a simple and fast centrality measure such as Degree centrality can outperform other more time-consuming measures.
"Pale as death" or "pâle comme la mort" : Frozen similes used as literary clichés
Jun 13, 2016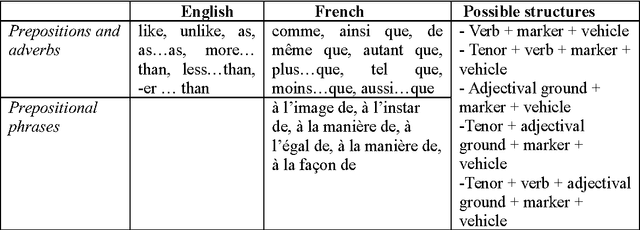

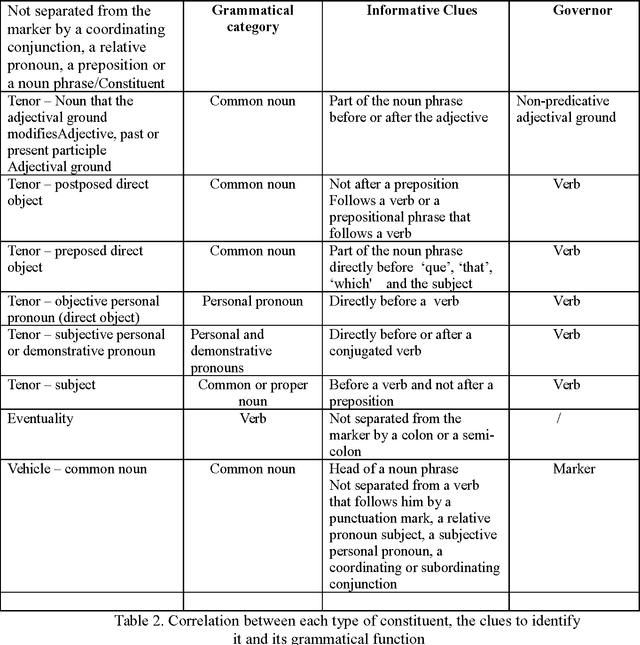

The present study is focused on the automatic identification and description of frozen similes in British and French novels written between the 19 th century and the beginning of the 20 th century. Two main patterns of frozen similes were considered: adjectival ground + simile marker + nominal vehicle (e.g. happy as a lark) and eventuality + simile marker + nominal vehicle (e.g. sleep like a top). All potential similes and their components were first extracted using a rule-based algorithm. Then, frozen similes were identified based on reference lists of existing similes and semantic distance between the tenor and the vehicle. The results obtained tend to confirm the fact that frozen similes are not used haphazardly in literary texts. In addition, contrary to how they are often presented, frozen similes often go beyond the ground or the eventuality and the vehicle to also include the tenor.
Investigating the stylistic relevance of adjective and verb simile markers
Nov 10, 2015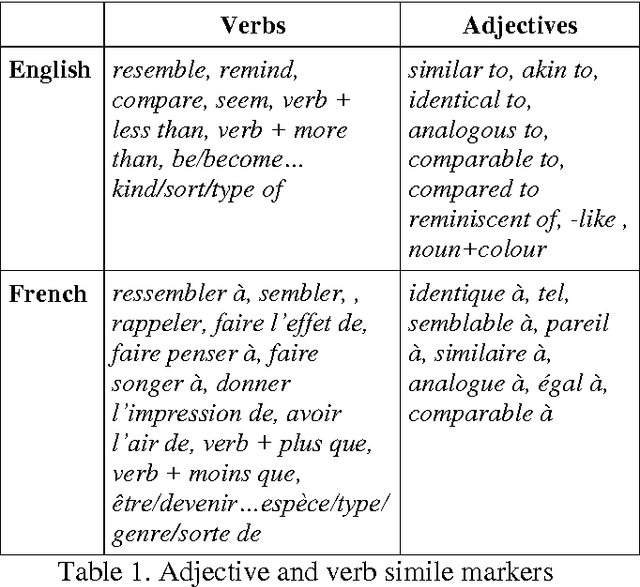
Similes play an important role in literary texts not only as rhetorical devices and as figures of speech but also because of their evocative power, their aptness for description and the relative ease with which they can be combined with other figures of speech (Israel et al. 2004). Detecting all types of simile constructions in a particular text therefore seems crucial when analysing the style of an author. Few research studies however have been dedicated to the study of less prominent simile markers in fictional prose and their relevance for stylistic studies. The present paper studies the frequency of adjective and verb simile markers in a corpus of British and French novels in order to determine which ones are really informative and worth including in a stylistic analysis. Furthermore, are those adjectives and verb simile markers used differently in both languages?
Automatic Detection of Reuses and Citations in Literary Texts
Apr 11, 2014



For more than forty years now, modern theories of literature (Compagnon, 1979) insist on the role of paraphrases, rewritings, citations, reciprocal borrowings and mutual contributions of any kinds. The notions of intertextuality, transtextuality, hypertextuality/hypotextuality, were introduced in the seventies and eighties to approach these phenomena. The careful analysis of these references is of particular interest in evaluating the distance that the creator voluntarily introduces with his/her masters. Phoebus is collaborative project that makes computer scientists from the University Pierre and Marie Curie (LIP6-UPMC) collaborate with the literary teams of Paris-Sorbonne University with the aim to develop efficient tools for literary studies that take advantage of modern computer science techniques. In this context, we have developed a piece of software that automatically detects and explores networks of textual reuses in classical literature. This paper describes the principles on which is based this program, the significant results that have already been obtained and the perspectives for the near future.