 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplex QA and language models hybrid architectures, Survey
Paper and Code
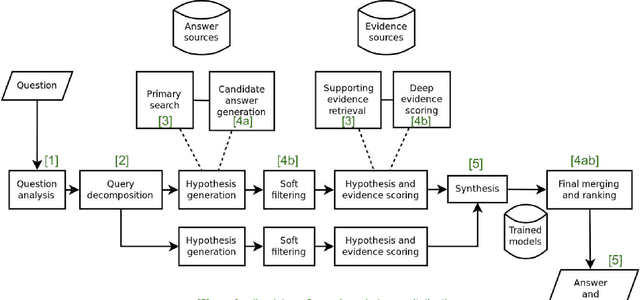
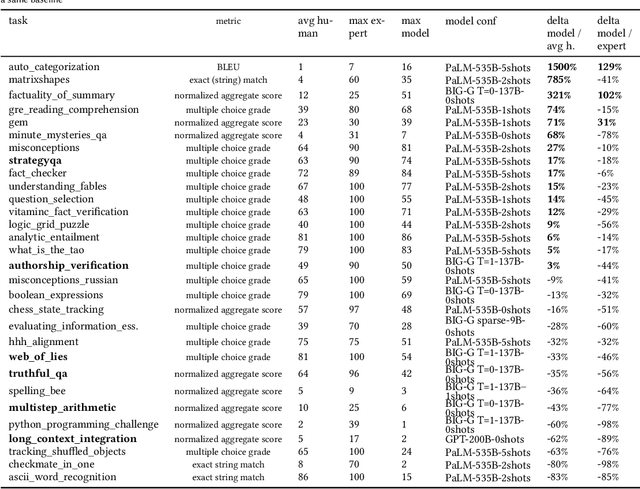
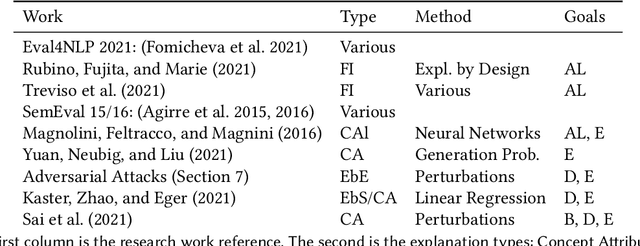
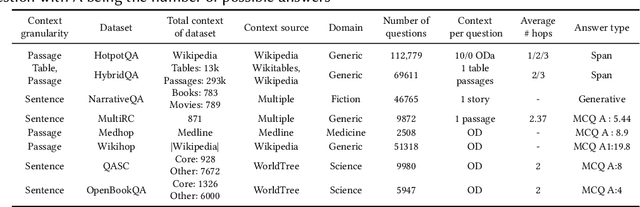
This paper provides a survey of the state of the art of hybrid language models architectures and strategies for "complex" question-answering (QA, CQA, CPS). Very large language models are good at leveraging public data on standard problems but once you want to tackle more specific complex questions or problems you may need specific architecture, knowledge, skills, tasks, methods, sensitive data, performance, human approval and versatile feedback... This survey extends findings from the robust community edited research papers BIG, BLOOM and HELM which open source, benchmark and analyze limits and challenges of large language models in terms of tasks complexity and strict evaluation on accuracy (e.g. fairness, robustness, toxicity, ...). It identifies the key elements used with Large Language Models (LLM) to solve complex questions or problems. Recent projects like ChatGPT and GALACTICA have allowed non-specialists to grasp the great potential as well as the equally strong limitations of language models in complex QA. Hybridizing these models with different components could allow to overcome these different limits and go much further. We discuss some challenges associated with complex QA, including domain adaptation, decomposition and efficient multi-step QA, long form QA, non-factoid QA, safety and multi-sensitivity data protection, multimodal search, hallucinations, QA explainability and truthfulness, time dimension. Therefore we review current solutions and promising strategies, using elements such as hybrid LLM architectures, human-in-the-loop reinforcement learning, prompting adaptation, neuro-symbolic and structured knowledge grounding, program synthesis, and others. We analyze existing solutions and provide an overview of the current research and trends in the area of complex QA.