 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBERT, can HE predict contrastive focus? Predicting and controlling prominence in neural TTS using a language model
Jul 04, 2022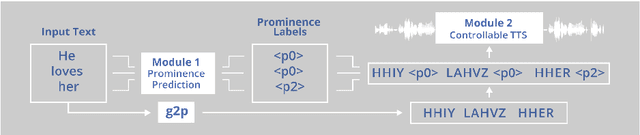

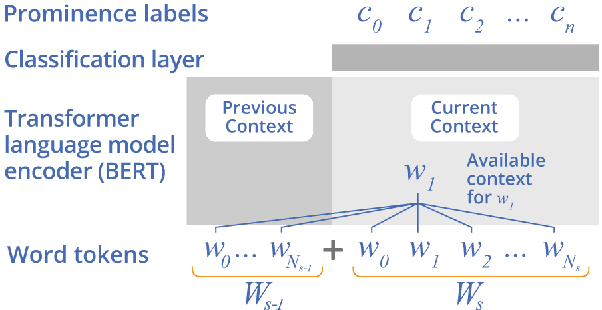
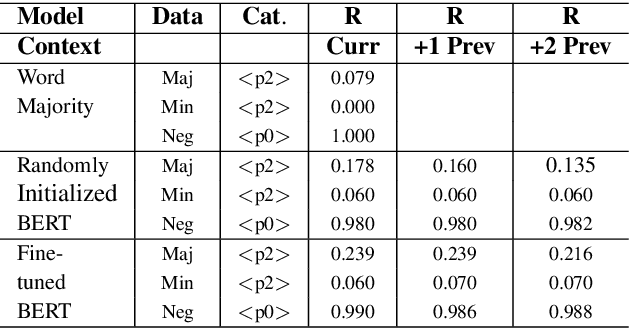
Several recent studies have tested the use of transformer language model representations to infer prosodic features for text-to-speech synthesis (TTS). While these studies have explored prosody in general, in this work, we look specifically at the prediction of contrastive focus on personal pronouns. This is a particularly challenging task as it often requires semantic, discursive and/or pragmatic knowledge to predict correctly. We collect a corpus of utterances containing contrastive focus and we evaluate the accuracy of a BERT model, finetuned to predict quantized acoustic prominence features, on these samples. We also investigate how past utterances can provide relevant information for this prediction. Furthermore, we evaluate the controllability of pronoun prominence in a TTS model conditioned on acoustic prominence features.
Alternate Endings: Improving Prosody for Incremental Neural TTS with Predicted Future Text Input
Feb 19, 2021

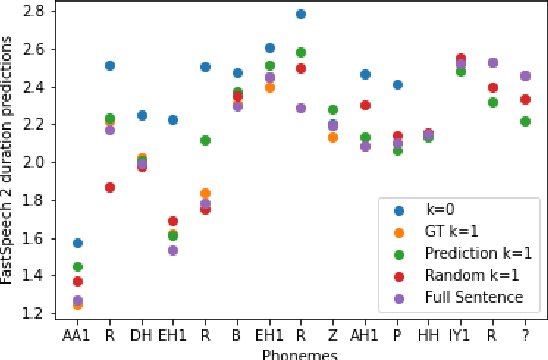
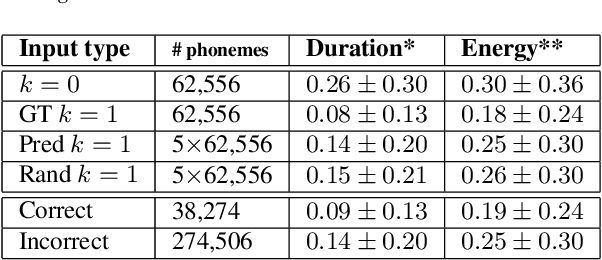
The prosody of a spoken word is determined by its surrounding context. In incremental text-to-speech synthesis, where the synthesizer produces an output before it has access to the complete input, the full context is often unknown which can result in a loss of naturalness in the synthesized speech. In this paper, we investigate whether the use of predicted future text can attenuate this loss. We compare several test conditions of next future word: (a) unknown (zero-word), (b) language model predicted, (c) randomly predicted and (d) ground-truth. We measure the prosodic features (pitch, energy and duration) and find that predicted text provides significant improvements over a zero-word lookahead, but only slight gains over random-word lookahead. We confirm these results with a perceptive test.
What the Future Brings: Investigating the Impact of Lookahead for Incremental Neural TTS
Sep 04, 2020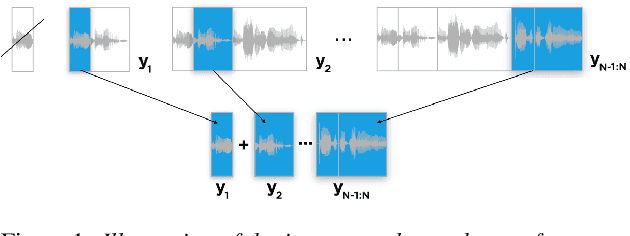

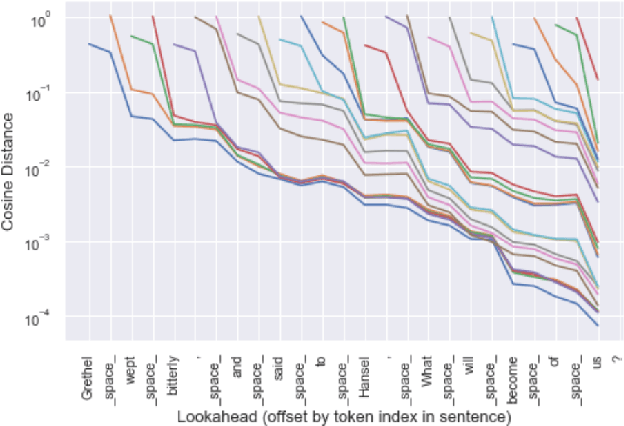
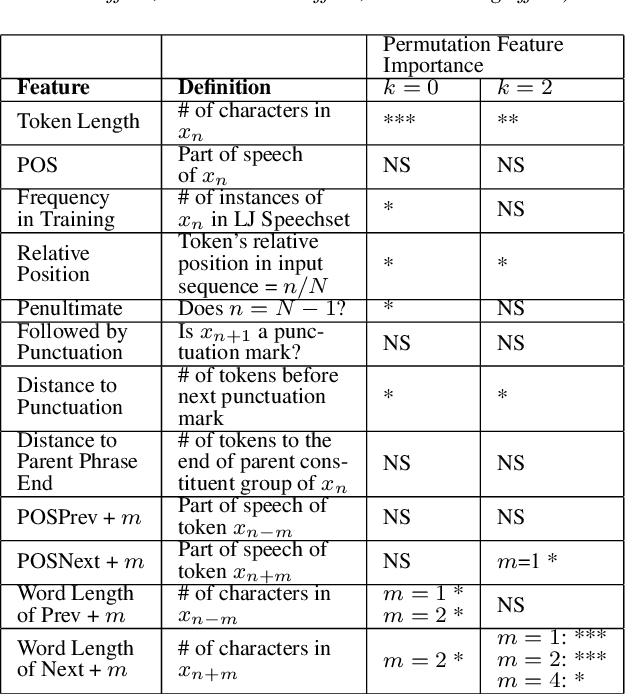
In incremental text to speech synthesis (iTTS), the synthesizer produces an audio output before it has access to the entire input sentence. In this paper, we study the behavior of a neural sequence-to-sequence TTS system when used in an incremental mode, i.e. when generating speech output for token n, the system has access to n + k tokens from the text sequence. We first analyze the impact of this incremental policy on the evolution of the encoder representations of token n for different values of k (the lookahead parameter). The results show that, on average, tokens travel 88% of the way to their full context representation with a one-word lookahead and 94% after 2 words. We then investigate which text features are the most influential on the evolution towards the final representation using a random forest analysis. The results show that the most salient factors are related to token length. We finally evaluate the effects of lookahead k at the decoder level, using a MUSHRA listening test. This test shows results that contrast with the above high figures: speech synthesis quality obtained with 2 word-lookahead is significantly lower than the one obtained with the full sentence.