 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat the Future Brings: Investigating the Impact of Lookahead for Incremental Neural TTS
Paper and Code
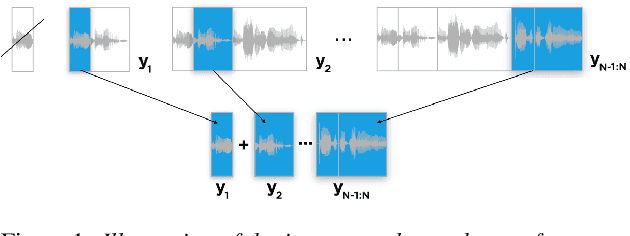

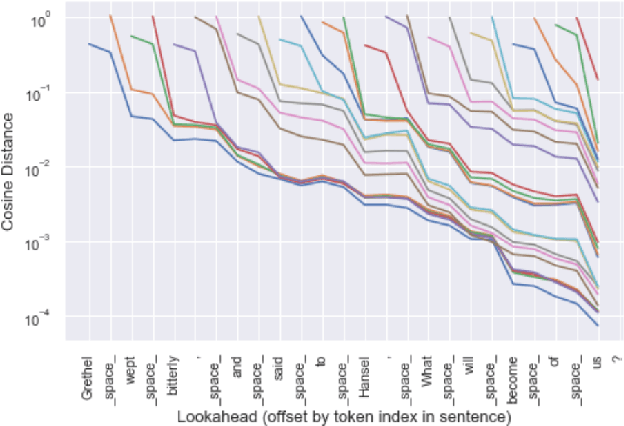
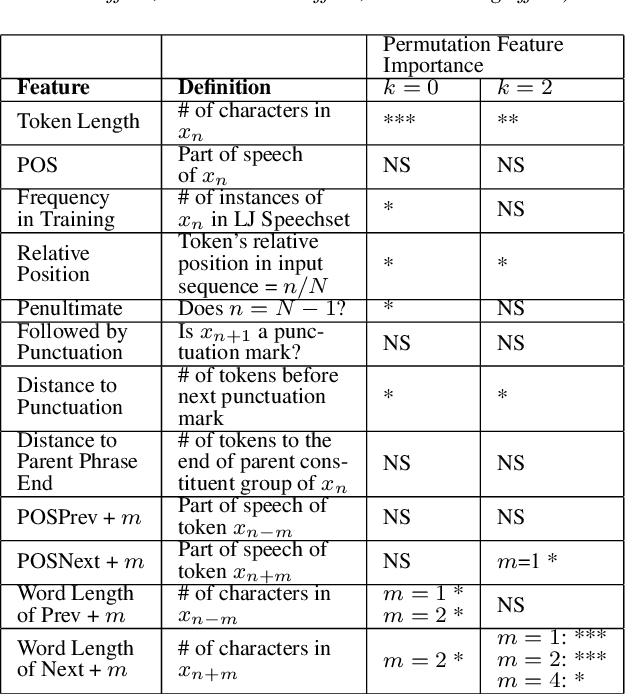
In incremental text to speech synthesis (iTTS), the synthesizer produces an audio output before it has access to the entire input sentence. In this paper, we study the behavior of a neural sequence-to-sequence TTS system when used in an incremental mode, i.e. when generating speech output for token n, the system has access to n + k tokens from the text sequence. We first analyze the impact of this incremental policy on the evolution of the encoder representations of token n for different values of k (the lookahead parameter). The results show that, on average, tokens travel 88% of the way to their full context representation with a one-word lookahead and 94% after 2 words. We then investigate which text features are the most influential on the evolution towards the final representation using a random forest analysis. The results show that the most salient factors are related to token length. We finally evaluate the effects of lookahead k at the decoder level, using a MUSHRA listening test. This test shows results that contrast with the above high figures: speech synthesis quality obtained with 2 word-lookahead is significantly lower than the one obtained with the full sentence.