 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDOLFIN -- Document-Level Financial test set for Machine Translation
Feb 05, 2025Despite the strong research interest in document-level Machine Translation (MT), the test sets dedicated to this task are still scarce. The existing test sets mainly cover topics from the general domain and fall short on specialised domains, such as legal and financial. Also, in spite of their document-level aspect, they still follow a sentence-level logic that does not allow for including certain linguistic phenomena such as information reorganisation. In this work, we aim to fill this gap by proposing a novel test set: DOLFIN. The dataset is built from specialised financial documents, and it makes a step towards true document-level MT by abandoning the paradigm of perfectly aligned sentences, presenting data in units of sections rather than sentences. The test set consists of an average of 1950 aligned sections for five language pairs. We present a detailed data collection pipeline that can serve as inspiration for aligning new document-level datasets. We demonstrate the usefulness and quality of this test set by evaluating a number of models. Our results show that the test set is able to discriminate between context-sensitive and context-agnostic models and shows the weaknesses when models fail to accurately translate financial texts. The test set is made public for the community.
Online Versus Offline NMT Quality: An In-depth Analysis on English-German and German-English
Jun 01, 2020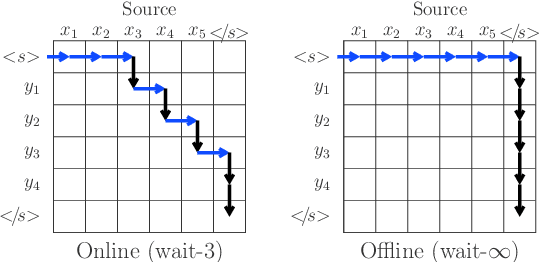
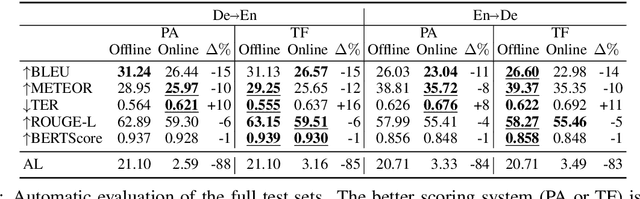


We conduct in this work an evaluation study comparing offline and online neural machine translation architectures. Two sequence-to-sequence models: convolutional Pervasive Attention (Elbayad et al. 2018) and attention-based Transformer (Vaswani et al. 2017) are considered. We investigate, for both architectures, the impact of online decoding constraints on the translation quality through a carefully designed human evaluation on English-German and German-English language pairs, the latter being particularly sensitive to latency constraints. The evaluation results allow us to identify the strengths and shortcomings of each model when we shift to the online setup.