 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe LLM Pro Finance Suite: Multilingual Large Language Models for Financial Applications
Nov 07, 2025The financial industry's growing demand for advanced natural language processing (NLP) capabilities has highlighted the limitations of generalist large language models (LLMs) in handling domain-specific financial tasks. To address this gap, we introduce the LLM Pro Finance Suite, a collection of five instruction-tuned LLMs (ranging from 8B to 70B parameters) specifically designed for financial applications. Our approach focuses on enhancing generalist instruction-tuned models, leveraging their existing strengths in instruction following, reasoning, and toxicity control, while fine-tuning them on a curated, high-quality financial corpus comprising over 50% finance-related data in English, French, and German. We evaluate the LLM Pro Finance Suite on a comprehensive financial benchmark suite, demonstrating consistent improvement over state-of-the-art baselines in finance-oriented tasks and financial translation. Notably, our models maintain the strong general-domain capabilities of their base models, ensuring reliable performance across non-specialized tasks. This dual proficiency, enhanced financial expertise without compromise on general abilities, makes the LLM Pro Finance Suite an ideal drop-in replacement for existing LLMs in financial workflows, offering improved domain-specific performance while preserving overall versatility. We publicly release two 8B-parameters models to foster future research and development in financial NLP applications: https://huggingface.co/collections/DragonLLM/llm-open-finance.
DOLFIN -- Document-Level Financial test set for Machine Translation
Feb 05, 2025Despite the strong research interest in document-level Machine Translation (MT), the test sets dedicated to this task are still scarce. The existing test sets mainly cover topics from the general domain and fall short on specialised domains, such as legal and financial. Also, in spite of their document-level aspect, they still follow a sentence-level logic that does not allow for including certain linguistic phenomena such as information reorganisation. In this work, we aim to fill this gap by proposing a novel test set: DOLFIN. The dataset is built from specialised financial documents, and it makes a step towards true document-level MT by abandoning the paradigm of perfectly aligned sentences, presenting data in units of sections rather than sentences. The test set consists of an average of 1950 aligned sections for five language pairs. We present a detailed data collection pipeline that can serve as inspiration for aligning new document-level datasets. We demonstrate the usefulness and quality of this test set by evaluating a number of models. Our results show that the test set is able to discriminate between context-sensitive and context-agnostic models and shows the weaknesses when models fail to accurately translate financial texts. The test set is made public for the community.
Large Language Model Adaptation for Financial Sentiment Analysis
Jan 26, 2024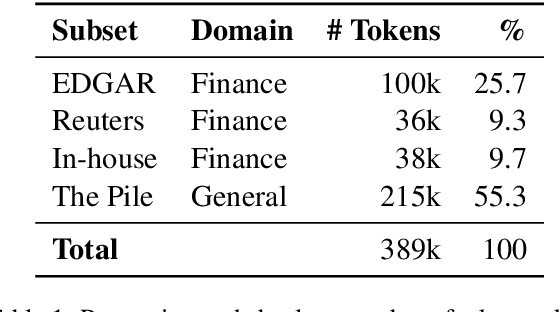

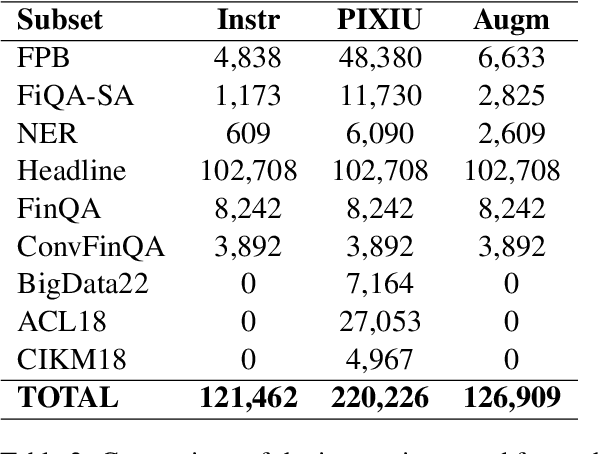
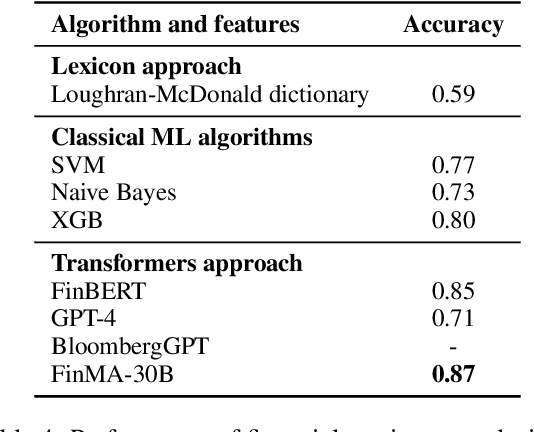
Natural language processing (NLP) has recently gained relevance within financial institutions by providing highly valuable insights into companies and markets' financial documents. However, the landscape of the financial domain presents extra challenges for NLP, due to the complexity of the texts and the use of specific terminology. Generalist language models tend to fall short in tasks specifically tailored for finance, even when using large language models (LLMs) with great natural language understanding and generative capabilities. This paper presents a study on LLM adaptation methods targeted at the financial domain and with high emphasis on financial sentiment analysis. To this purpose, two foundation models with less than 1.5B parameters have been adapted using a wide range of strategies. We show that through careful fine-tuning on both financial documents and instructions, these foundation models can be adapted to the target domain. Moreover, we observe that small LLMs have comparable performance to larger scale models, while being more efficient in terms of parameters and data. In addition to the models, we show how to generate artificial instructions through LLMs to augment the number of samples of the instruction dataset.