 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCo-GRPO: Co-Optimized Group Relative Policy Optimization for Masked Diffusion Model
Dec 25, 2025Recently, Masked Diffusion Models (MDMs) have shown promising potential across vision, language, and cross-modal generation. However, a notable discrepancy exists between their training and inference procedures. In particular, MDM inference is a multi-step, iterative process governed not only by the model itself but also by various schedules that dictate the token-decoding trajectory (e.g., how many tokens to decode at each step). In contrast, MDMs are typically trained using a simplified, single-step BERT-style objective that masks a subset of tokens and predicts all of them simultaneously. This step-level simplification fundamentally disconnects the training paradigm from the trajectory-level nature of inference, leaving the inference schedules never optimized during training. In this paper, we introduce Co-GRPO, which reformulates MDM generation as a unified Markov Decision Process (MDP) that jointly incorporates both the model and the inference schedule. By applying Group Relative Policy Optimization at the trajectory level, Co-GRPO cooperatively optimizes model parameters and schedule parameters under a shared reward, without requiring costly backpropagation through the multi-step generation process. This holistic optimization aligns training with inference more thoroughly and substantially improves generation quality. Empirical results across four benchmarks-ImageReward, HPS, GenEval, and DPG-Bench-demonstrate the effectiveness of our approach. For more details, please refer to our project page: https://co-grpo.github.io/ .
The LLM Pro Finance Suite: Multilingual Large Language Models for Financial Applications
Nov 07, 2025The financial industry's growing demand for advanced natural language processing (NLP) capabilities has highlighted the limitations of generalist large language models (LLMs) in handling domain-specific financial tasks. To address this gap, we introduce the LLM Pro Finance Suite, a collection of five instruction-tuned LLMs (ranging from 8B to 70B parameters) specifically designed for financial applications. Our approach focuses on enhancing generalist instruction-tuned models, leveraging their existing strengths in instruction following, reasoning, and toxicity control, while fine-tuning them on a curated, high-quality financial corpus comprising over 50% finance-related data in English, French, and German. We evaluate the LLM Pro Finance Suite on a comprehensive financial benchmark suite, demonstrating consistent improvement over state-of-the-art baselines in finance-oriented tasks and financial translation. Notably, our models maintain the strong general-domain capabilities of their base models, ensuring reliable performance across non-specialized tasks. This dual proficiency, enhanced financial expertise without compromise on general abilities, makes the LLM Pro Finance Suite an ideal drop-in replacement for existing LLMs in financial workflows, offering improved domain-specific performance while preserving overall versatility. We publicly release two 8B-parameters models to foster future research and development in financial NLP applications: https://huggingface.co/collections/DragonLLM/llm-open-finance.
Large Language Model Adaptation for Financial Sentiment Analysis
Jan 26, 2024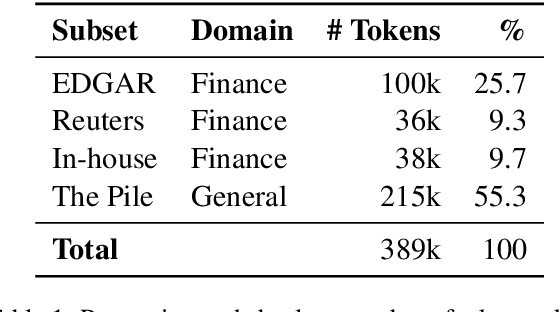

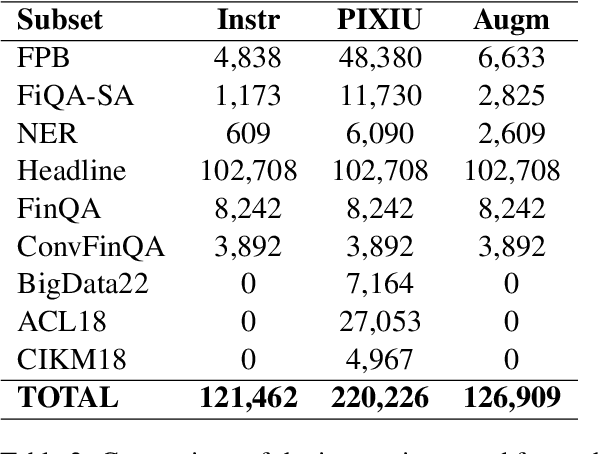
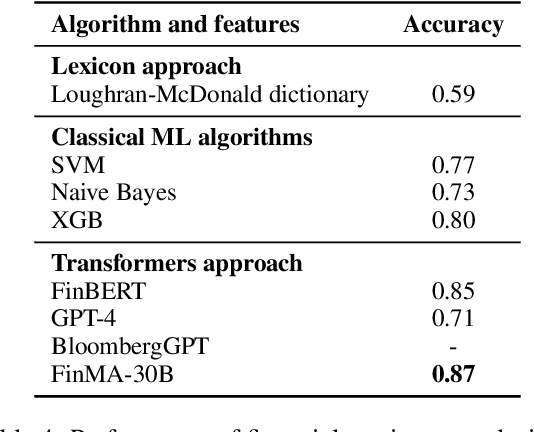
Natural language processing (NLP) has recently gained relevance within financial institutions by providing highly valuable insights into companies and markets' financial documents. However, the landscape of the financial domain presents extra challenges for NLP, due to the complexity of the texts and the use of specific terminology. Generalist language models tend to fall short in tasks specifically tailored for finance, even when using large language models (LLMs) with great natural language understanding and generative capabilities. This paper presents a study on LLM adaptation methods targeted at the financial domain and with high emphasis on financial sentiment analysis. To this purpose, two foundation models with less than 1.5B parameters have been adapted using a wide range of strategies. We show that through careful fine-tuning on both financial documents and instructions, these foundation models can be adapted to the target domain. Moreover, we observe that small LLMs have comparable performance to larger scale models, while being more efficient in terms of parameters and data. In addition to the models, we show how to generate artificial instructions through LLMs to augment the number of samples of the instruction dataset.
A Machine Learning Approach for Recruitment Prediction in Clinical Trial Design
Nov 14, 2021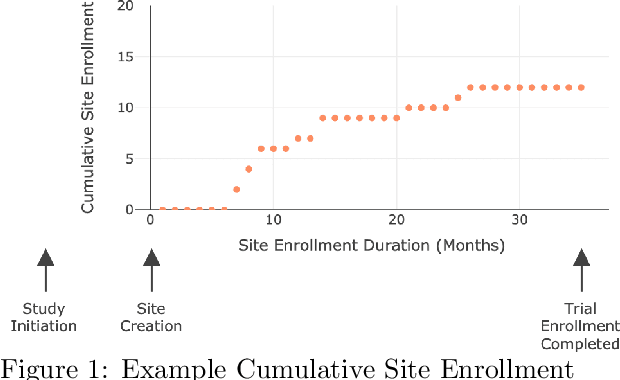
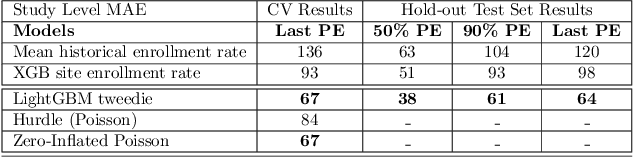
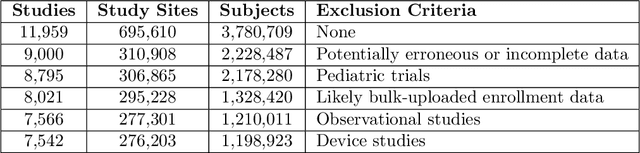

Significant advancements have been made in recent years to optimize patient recruitment for clinical trials, however, improved methods for patient recruitment prediction are needed to support trial site selection and to estimate appropriate enrollment timelines in the trial design stage. In this paper, using data from thousands of historical clinical trials, we explore machine learning methods to predict the number of patients enrolled per month at a clinical trial site over the course of a trial's enrollment duration. We show that these methods can reduce the error that is observed with current industry standards and propose opportunities for further improvement.
BERT-XML: Large Scale Automated ICD Coding Using BERT Pretraining
May 26, 2020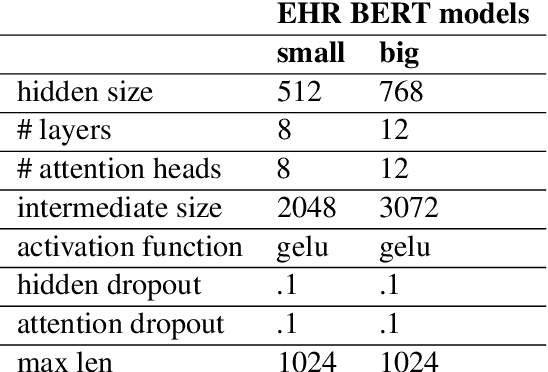
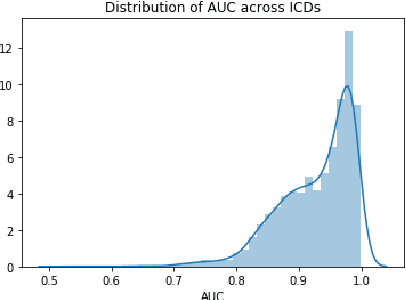
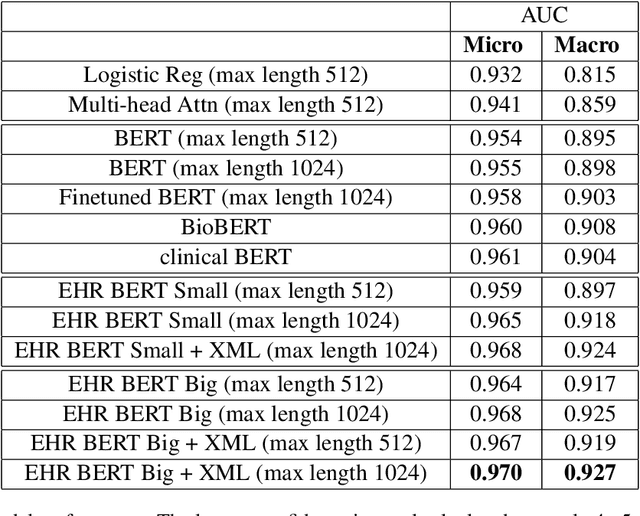

Clinical interactions are initially recorded and documented in free text medical notes. ICD coding is the task of classifying and coding all diagnoses, symptoms and procedures associated with a patient's visit. The process is often manual and extremely time-consuming and expensive for hospitals. In this paper, we propose a machine learning model, BERT-XML, for large scale automated ICD coding from EHR notes, utilizing recently developed unsupervised pretraining that have achieved state of the art performance on a variety of NLP tasks. We train a BERT model from scratch on EHR notes, learning with vocabulary better suited for EHR tasks and thus outperform off-the-shelf models. We adapt the BERT architecture for ICD coding with multi-label attention. While other works focus on small public medical datasets, we have produced the first large scale ICD-10 classification model using millions of EHR notes to predict thousands of unique ICD codes.
An Image Based Visual Servo Approach with Deep Learning for Robotic Manipulation
Sep 17, 2019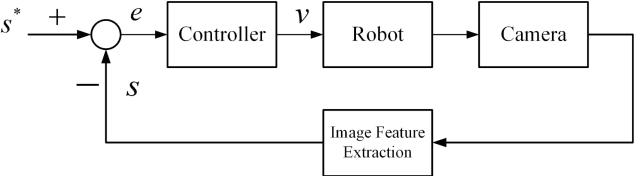
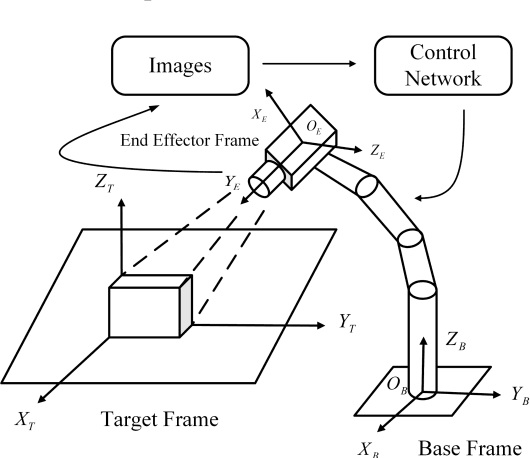
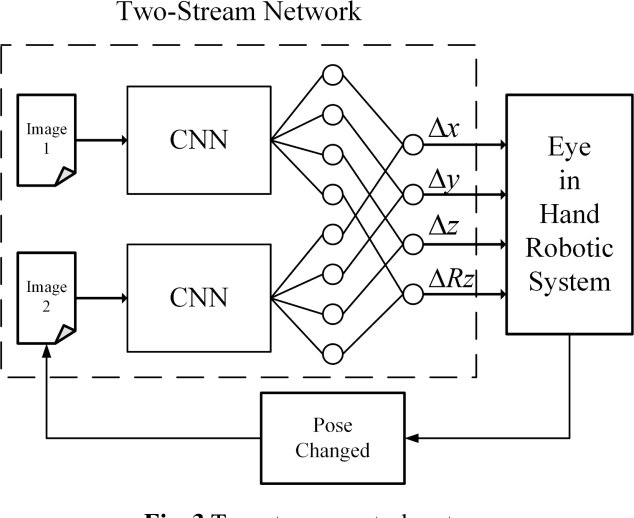
Aiming at the difficulty of extracting image features and estimating the Jacobian matrix in image based visual servo, this paper proposes an image based visual servo approach with deep learning. With the powerful learning capabilities of convolutional neural networks(CNN), autonomous learning to extract features from images and fitting the nonlinear relationships from image space to task space is achieved, which can greatly facilitate the image based visual servo procedure. Based on the above ideas a two-stream network based on convolutional neural network is designed and the corresponding control scheme is proposed to realize the four degrees of freedom visual servo of the robot manipulator. Collecting images of observed target under different pose parameters of the manipulator as training samples for CNN, the trained network can be used to estimate the nonlinear relationship from 2D image space to 3D Cartesian space. The two-stream network takes the current image and the desirable image as inputs and makes them equal to guide the manipulator to the desirable pose. The effectiveness of the approach is verified with experimental results.
Deep EHR: Chronic Disease Prediction Using Medical Notes
Aug 15, 2018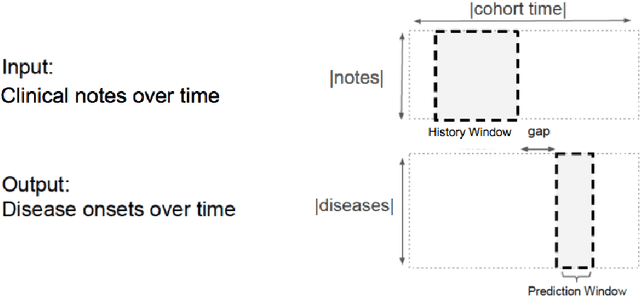

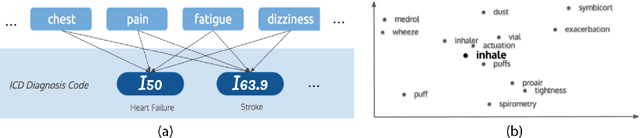
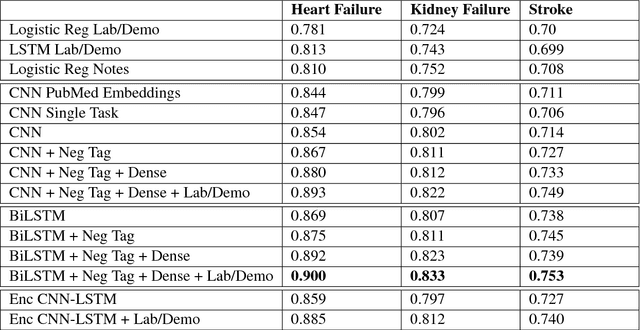
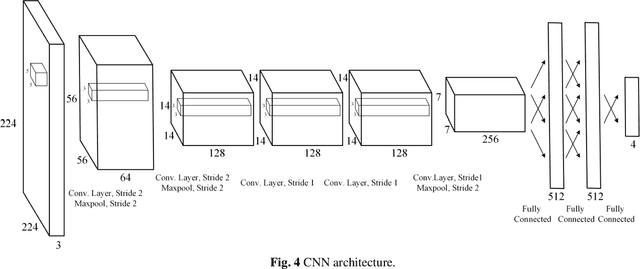
Early detection of preventable diseases is important for better disease management, improved inter-ventions, and more efficient health-care resource allocation. Various machine learning approacheshave been developed to utilize information in Electronic Health Record (EHR) for this task. Majorityof previous attempts, however, focus on structured fields and lose the vast amount of information inthe unstructured notes. In this work we propose a general multi-task framework for disease onsetprediction that combines both free-text medical notes and structured information. We compareperformance of different deep learning architectures including CNN, LSTM and hierarchical models.In contrast to traditional text-based prediction models, our approach does not require disease specificfeature engineering, and can handle negations and numerical values that exist in the text. Ourresults on a cohort of about 1 million patients show that models using text outperform modelsusing just structured data, and that models capable of using numerical values and negations in thetext, in addition to the raw text, further improve performance. Additionally, we compare differentvisualization methods for medical professionals to interpret model predictions.