 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-Driven Research for Databases
Apr 08, 2026As the complexity of modern workloads and hardware increasingly outpaces human research and engineering capacity, existing methods for database performance optimization struggle to keep pace. To address this gap, a new class of techniques, termed AI-Driven Research for Systems (ADRS), uses large language models to automate solution discovery. This approach shifts optimization from manual system design to automated code generation. The key obstacle, however, in applying ADRS is the evaluation pipeline. Since these frameworks rapidly generate hundreds of candidates without human supervision, they depend on fast and accurate feedback from evaluators to converge on effective solutions. Building such evaluators is especially difficult for complex database systems. To enable the practical application of ADRS in this domain, we propose automating the design of evaluators by co-evolving them with the solutions. We demonstrate the effectiveness of this approach through three case studies optimizing buffer management, query rewriting, and index selection. Our automated evaluators enable the discovery of novel algorithms that outperform state-of-the-art baselines (e.g., a deterministic query rewrite policy that achieves up to 6.8x lower latency), demonstrating that addressing the evaluation bottleneck unlocks the potential of ADRS to generate highly optimized, deployable code for next-generation data systems.
EigenScore: OOD Detection using Covariance in Diffusion Models
Oct 08, 2025


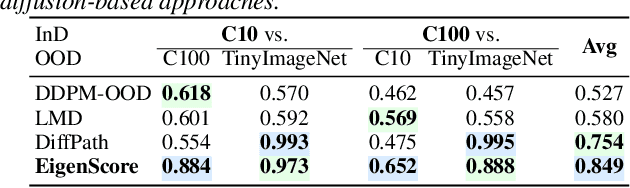
Out-of-distribution (OOD) detection is critical for the safe deployment of machine learning systems in safety-sensitive domains. Diffusion models have recently emerged as powerful generative models, capable of capturing complex data distributions through iterative denoising. Building on this progress, recent work has explored their potential for OOD detection. We propose EigenScore, a new OOD detection method that leverages the eigenvalue spectrum of the posterior covariance induced by a diffusion model. We argue that posterior covariance provides a consistent signal of distribution shift, leading to larger trace and leading eigenvalues on OOD inputs, yielding a clear spectral signature. We further provide analysis explicitly linking posterior covariance to distribution mismatch, establishing it as a reliable signal for OOD detection. To ensure tractability, we adopt a Jacobian-free subspace iteration method to estimate the leading eigenvalues using only forward evaluations of the denoiser. Empirically, EigenScore achieves SOTA performance, with up to 5% AUROC improvement over the best baseline. Notably, it remains robust in near-OOD settings such as CIFAR-10 vs CIFAR-100, where existing diffusion-based methods often fail.
LiGNN: Graph Neural Networks at LinkedIn
Feb 17, 2024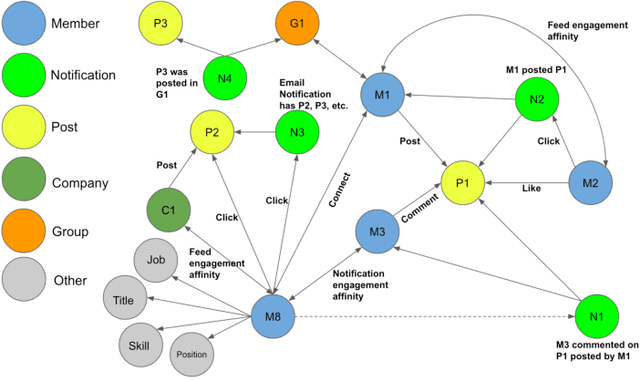

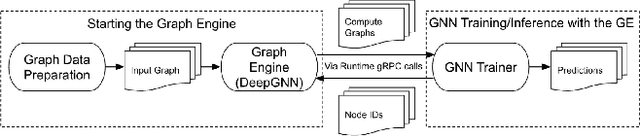

In this paper, we present LiGNN, a deployed large-scale Graph Neural Networks (GNNs) Framework. We share our insight on developing and deployment of GNNs at large scale at LinkedIn. We present a set of algorithmic improvements to the quality of GNN representation learning including temporal graph architectures with long term losses, effective cold start solutions via graph densification, ID embeddings and multi-hop neighbor sampling. We explain how we built and sped up by 7x our large-scale training on LinkedIn graphs with adaptive sampling of neighbors, grouping and slicing of training data batches, specialized shared-memory queue and local gradient optimization. We summarize our deployment lessons and learnings gathered from A/B test experiments. The techniques presented in this work have contributed to an approximate relative improvements of 1% of Job application hearing back rate, 2% Ads CTR lift, 0.5% of Feed engaged daily active users, 0.2% session lift and 0.1% weekly active user lift from people recommendation. We believe that this work can provide practical solutions and insights for engineers who are interested in applying Graph neural networks at large scale.
A Novel Cross-Perturbation for Single Domain Generalization
Aug 02, 2023

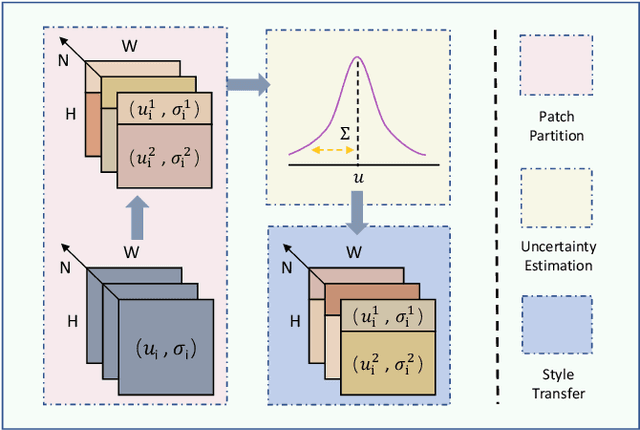

Single domain generalization aims to enhance the ability of the model to generalize to unknown domains when trained on a single source domain. However, the limited diversity in the training data hampers the learning of domain-invariant features, resulting in compromised generalization performance. To address this, data perturbation (augmentation) has emerged as a crucial method to increase data diversity. Nevertheless, existing perturbation methods often focus on either image-level or feature-level perturbations independently, neglecting their synergistic effects. To overcome these limitations, we propose CPerb, a simple yet effective cross-perturbation method. Specifically, CPerb utilizes both horizontal and vertical operations. Horizontally, it applies image-level and feature-level perturbations to enhance the diversity of the training data, mitigating the issue of limited diversity in single-source domains. Vertically, it introduces multi-route perturbation to learn domain-invariant features from different perspectives of samples with the same semantic category, thereby enhancing the generalization capability of the model. Additionally, we propose MixPatch, a novel feature-level perturbation method that exploits local image style information to further diversify the training data. Extensive experiments on various benchmark datasets validate the effectiveness of our method.
Density peak clustering using tensor network
Feb 01, 2023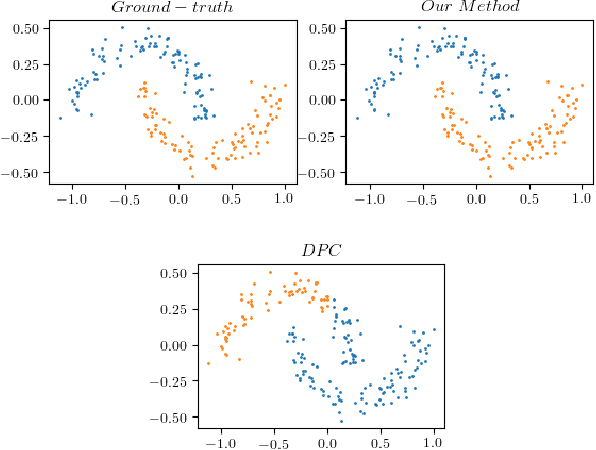


Tensor networks, which have been traditionally used to simulate many-body physics, have recently gained significant attention in the field of machine learning due to their powerful representation capabilities. In this work, we propose a density-based clustering algorithm inspired by tensor networks. We encode classical data into tensor network states on an extended Hilbert space and train the tensor network states to capture the features of the clusters. Here, we define density and related concepts in terms of fidelity, rather than using a classical distance measure. We evaluate the performance of our algorithm on six synthetic data sets, four real world data sets, and three commonly used computer vision data sets. The results demonstrate that our method provides state-of-the-art performance on several synthetic data sets and real world data sets, even when the number of clusters is unknown. Additionally, our algorithm performs competitively with state-of-the-art algorithms on the MNIST, USPS, and Fashion-MNIST image data sets. These findings reveal the great potential of tensor networks for machine learning applications.
A Machine Learning Approach for Recruitment Prediction in Clinical Trial Design
Nov 14, 2021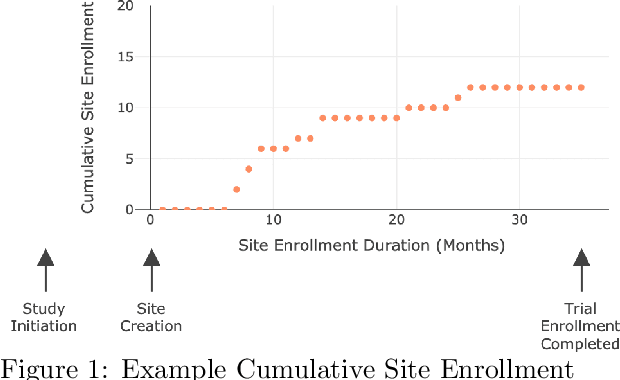
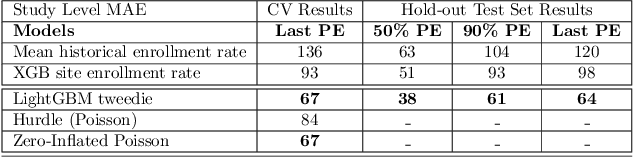
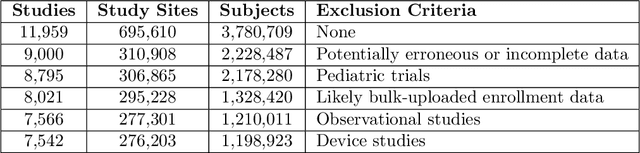

Significant advancements have been made in recent years to optimize patient recruitment for clinical trials, however, improved methods for patient recruitment prediction are needed to support trial site selection and to estimate appropriate enrollment timelines in the trial design stage. In this paper, using data from thousands of historical clinical trials, we explore machine learning methods to predict the number of patients enrolled per month at a clinical trial site over the course of a trial's enrollment duration. We show that these methods can reduce the error that is observed with current industry standards and propose opportunities for further improvement.