 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBERT-XML: Large Scale Automated ICD Coding Using BERT Pretraining
May 26, 2020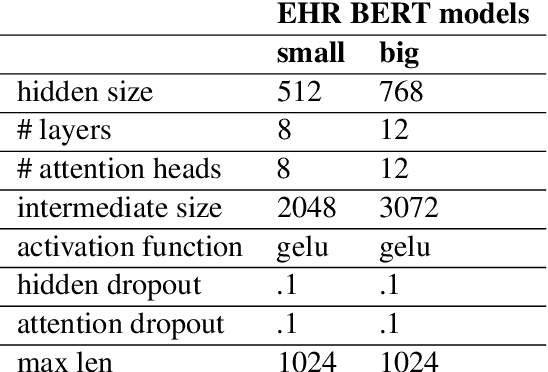
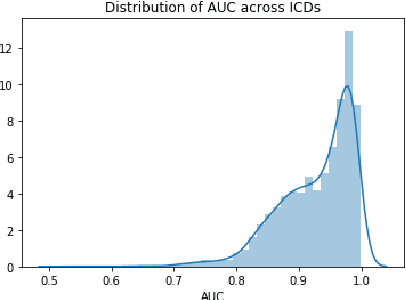
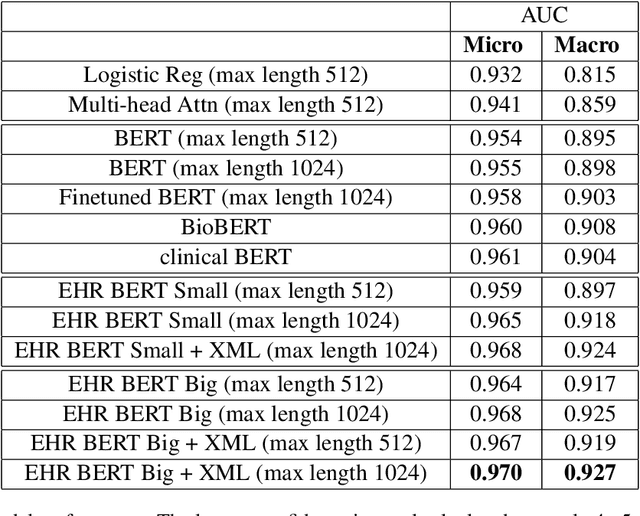

Clinical interactions are initially recorded and documented in free text medical notes. ICD coding is the task of classifying and coding all diagnoses, symptoms and procedures associated with a patient's visit. The process is often manual and extremely time-consuming and expensive for hospitals. In this paper, we propose a machine learning model, BERT-XML, for large scale automated ICD coding from EHR notes, utilizing recently developed unsupervised pretraining that have achieved state of the art performance on a variety of NLP tasks. We train a BERT model from scratch on EHR notes, learning with vocabulary better suited for EHR tasks and thus outperform off-the-shelf models. We adapt the BERT architecture for ICD coding with multi-label attention. While other works focus on small public medical datasets, we have produced the first large scale ICD-10 classification model using millions of EHR notes to predict thousands of unique ICD codes.
Deep EHR: Chronic Disease Prediction Using Medical Notes
Aug 15, 2018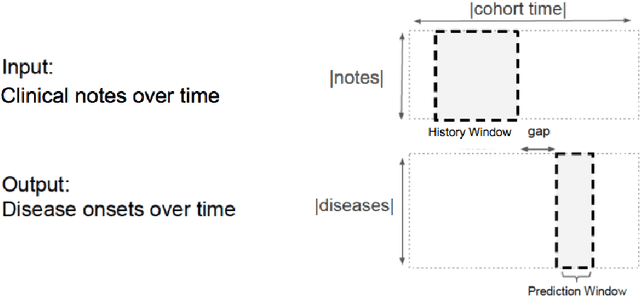

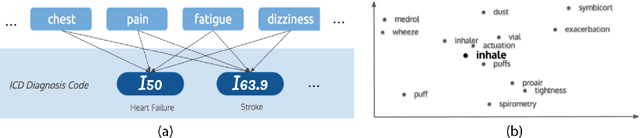
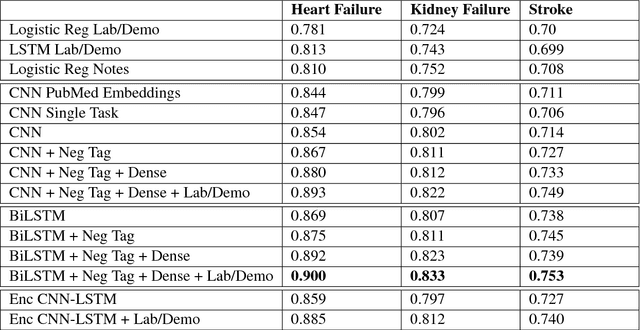
Early detection of preventable diseases is important for better disease management, improved inter-ventions, and more efficient health-care resource allocation. Various machine learning approacheshave been developed to utilize information in Electronic Health Record (EHR) for this task. Majorityof previous attempts, however, focus on structured fields and lose the vast amount of information inthe unstructured notes. In this work we propose a general multi-task framework for disease onsetprediction that combines both free-text medical notes and structured information. We compareperformance of different deep learning architectures including CNN, LSTM and hierarchical models.In contrast to traditional text-based prediction models, our approach does not require disease specificfeature engineering, and can handle negations and numerical values that exist in the text. Ourresults on a cohort of about 1 million patients show that models using text outperform modelsusing just structured data, and that models capable of using numerical values and negations in thetext, in addition to the raw text, further improve performance. Additionally, we compare differentvisualization methods for medical professionals to interpret model predictions.
Iterated geometric harmonics for data imputation and reconstruction of missing data
Nov 04, 2014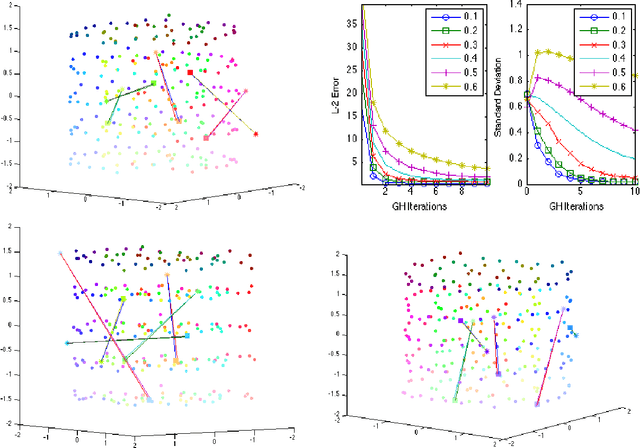



The method of geometric harmonics is adapted to the situation of incomplete data by means of the iterated geometric harmonics (IGH) scheme. The method is tested on natural and synthetic data sets with 50--500 data points and dimensionality of 400--10,000. Experiments suggest that the algorithm converges to a near optimal solution within 4--6 iterations, at runtimes of less than 30 minutes on a medium-grade desktop computer. The imputation of missing data values is applied to collections of damaged images (suffering from data annihilation rates of up to 70\%) which are reconstructed with a surprising degree of accuracy.