 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt engineering paradigms for medical applications: scoping review and recommendations for better practices
May 02, 2024



Prompt engineering is crucial for harnessing the potential of large language models (LLMs), especially in the medical domain where specialized terminology and phrasing is used. However, the efficacy of prompt engineering in the medical domain remains to be explored. In this work, 114 recent studies (2022-2024) applying prompt engineering in medicine, covering prompt learning (PL), prompt tuning (PT), and prompt design (PD) are reviewed. PD is the most prevalent (78 articles). In 12 papers, PD, PL, and PT terms were used interchangeably. ChatGPT is the most commonly used LLM, with seven papers using it for processing sensitive clinical data. Chain-of-Thought emerges as the most common prompt engineering technique. While PL and PT articles typically provide a baseline for evaluating prompt-based approaches, 64% of PD studies lack non-prompt-related baselines. We provide tables and figures summarizing existing work, and reporting recommendations to guide future research contributions.
Few shot clinical entity recognition in three languages: Masked language models outperform LLM prompting
Feb 20, 2024



Large Language Models are becoming the go-to solution for many natural language processing tasks, including in specialized domains where their few-shot capacities are expected to yield high performance in low-resource settings. Herein, we aim to assess the performance of Large Language Models for few shot clinical entity recognition in multiple languages. We evaluate named entity recognition in English, French and Spanish using 8 in-domain (clinical) and 6 out-domain gold standard corpora. We assess the performance of 10 auto-regressive language models using prompting and 16 masked language models used for text encoding in a biLSTM-CRF supervised tagger. We create a few-shot set-up by limiting the amount of annotated data available to 100 sentences. Our experiments show that although larger prompt-based models tend to achieve competitive F-measure for named entity recognition outside the clinical domain, this level of performance does not carry over to the clinical domain where lighter supervised taggers relying on masked language models perform better, even with the performance drop incurred from the few-shot set-up. In all experiments, the CO2 impact of masked language models is inferior to that of auto-regressive models. Results are consistent over the three languages and suggest that few-shot learning using Large language models is not production ready for named entity recognition in the clinical domain. Instead, models could be used for speeding-up the production of gold standard annotated data.
Toward Low-Cost End-to-End Spoken Language Understanding
Jul 01, 2022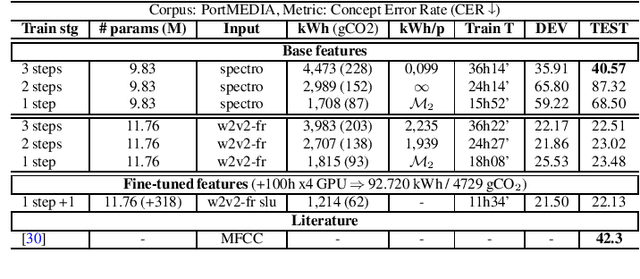
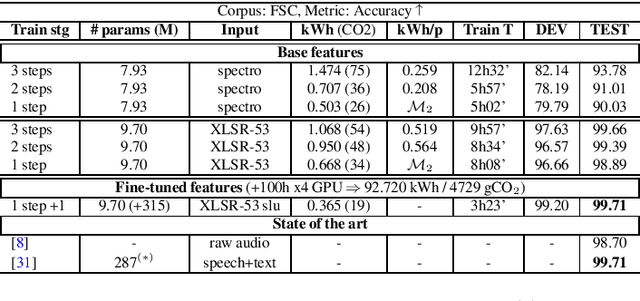
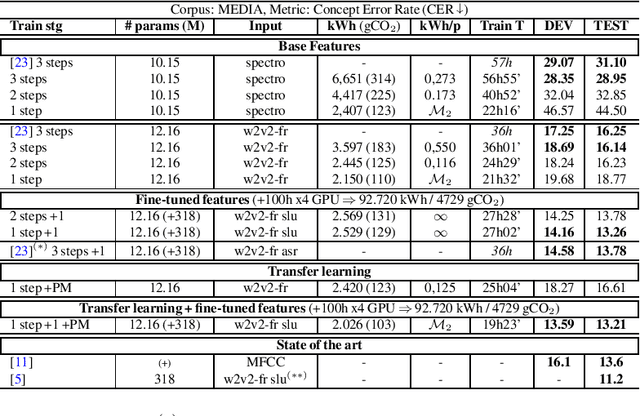
Recent advances in spoken language understanding benefited from Self-Supervised models trained on large speech corpora. For French, the LeBenchmark project has made such models available and has led to impressive progress on several tasks including spoken language understanding. These advances have a non-negligible cost in terms of computation time and energy consumption. In this paper, we compare several learning strategies trying to reduce such cost while keeping competitive performance. At the same time we propose an extensive analysis where we measure the cost of our models in terms of training time and electric energy consumption, hopefully promoting a comprehensive evaluation procedure. The experiments are performed on the FSC and MEDIA corpora, and show that it is possible to reduce the learning cost while maintaining state-of-the-art performance and using SSL models.
Vers la compréhension automatique de la parole bout-en-bout à moindre effort
Jul 01, 2022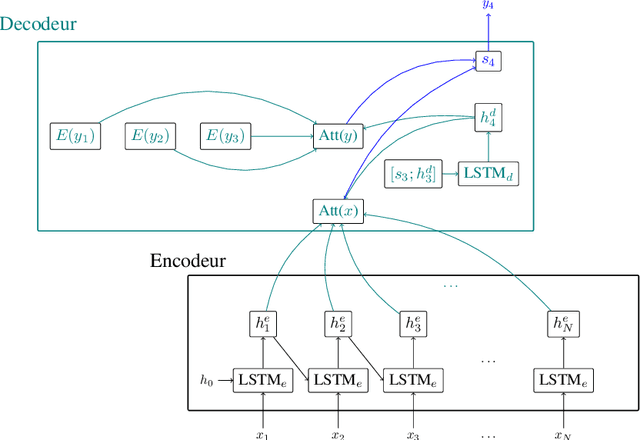
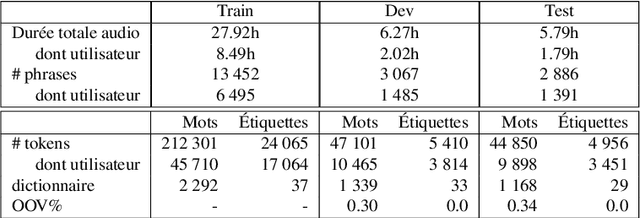
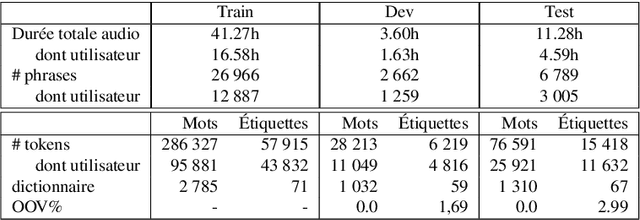
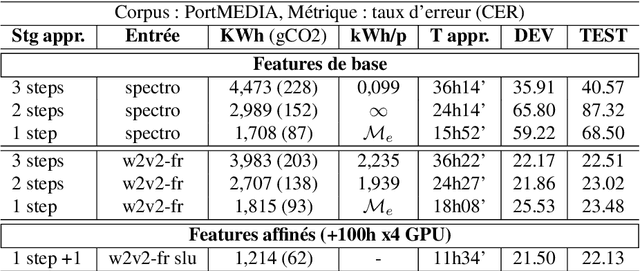
Recent advances in spoken language understanding benefited from Self-Supervised models trained on large speech corpora. For French, the LeBenchmark project has made such models available and has led to impressive progress on several tasks including spoken language understanding. These advances have a non-negligible cost in terms of computation time and energy consumption. In this paper, we compare several learning strategies aiming at reducing such cost while keeping competitive performances. The experiments are performed on the MEDIA corpus, and show that it is possible to reduce the learning cost while maintaining state-of-the-art performances.