Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVers la compréhension automatique de la parole bout-en-bout à moindre effort
Paper and Code
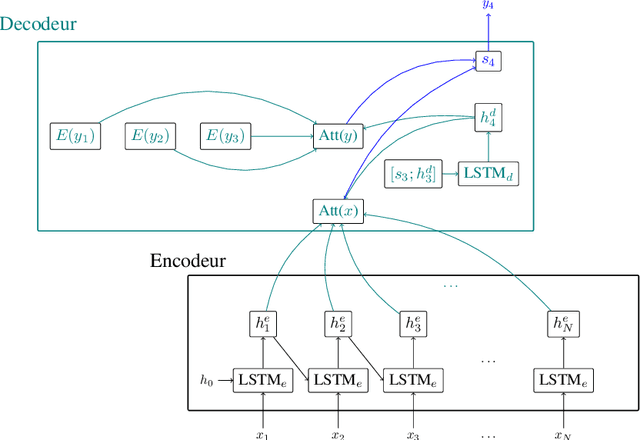
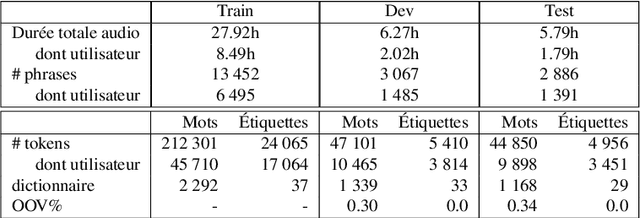
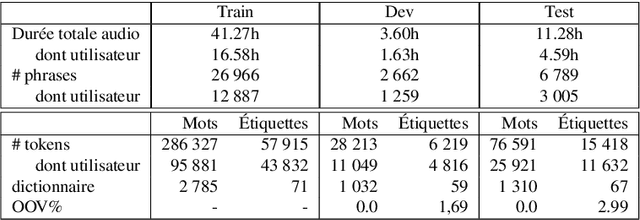
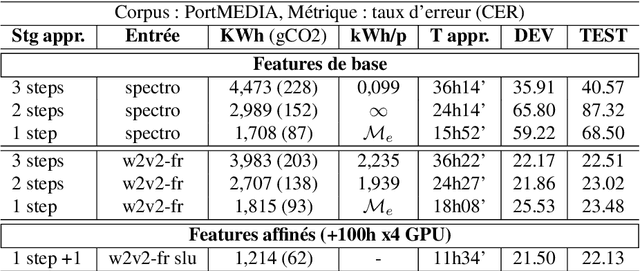
Recent advances in spoken language understanding benefited from Self-Supervised models trained on large speech corpora. For French, the LeBenchmark project has made such models available and has led to impressive progress on several tasks including spoken language understanding. These advances have a non-negligible cost in terms of computation time and energy consumption. In this paper, we compare several learning strategies aiming at reducing such cost while keeping competitive performances. The experiments are performed on the MEDIA corpus, and show that it is possible to reduce the learning cost while maintaining state-of-the-art performances.
* Language: French; Paper accepted for publication at the French
Conference TALN 2022; preliminary work for the Interspeech 2022 paper (coming
soon)
View paper on