 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTell me why: Visual foundation models as self-explainable classifiers
Feb 26, 2025Visual foundation models (VFMs) have become increasingly popular due to their state-of-the-art performance. However, interpretability remains crucial for critical applications. In this sense, self-explainable models (SEM) aim to provide interpretable classifiers that decompose predictions into a weighted sum of interpretable concepts. Despite their promise, recent studies have shown that these explanations often lack faithfulness. In this work, we combine VFMs with a novel prototypical architecture and specialized training objectives. By training only a lightweight head (approximately 1M parameters) on top of frozen VFMs, our approach (ProtoFM) offers an efficient and interpretable solution. Evaluations demonstrate that our approach achieves competitive classification performance while outperforming existing models across a range of interpretability metrics derived from the literature. Code is available at https://github.com/hturbe/proto-fm.
ProtoS-ViT: Visual foundation models for sparse self-explainable classifications
Jun 14, 2024



Prototypical networks aim to build intrinsically explainable models based on the linear summation of concepts. However, important challenges remain in the transparency, compactness, and meaningfulness of the explanations provided by these models. This work demonstrates how frozen pre-trained ViT backbones can be effectively turned into prototypical models for both general and domain-specific tasks, in our case biomedical image classifiers. By leveraging strong spatial features combined with a novel prototypical head, ProtoS-ViT surpasses existing prototypical models showing strong performance in terms of accuracy, compactness, and explainability. Model explainability is evaluated through an extensive set of quantitative and qualitative metrics which serve as a general benchmark for the development of prototypical models. Code is available at https://github.com/hturbe/protosvit.
Prompt engineering paradigms for medical applications: scoping review and recommendations for better practices
May 02, 2024



Prompt engineering is crucial for harnessing the potential of large language models (LLMs), especially in the medical domain where specialized terminology and phrasing is used. However, the efficacy of prompt engineering in the medical domain remains to be explored. In this work, 114 recent studies (2022-2024) applying prompt engineering in medicine, covering prompt learning (PL), prompt tuning (PT), and prompt design (PD) are reviewed. PD is the most prevalent (78 articles). In 12 papers, PD, PL, and PT terms were used interchangeably. ChatGPT is the most commonly used LLM, with seven papers using it for processing sensitive clinical data. Chain-of-Thought emerges as the most common prompt engineering technique. While PL and PT articles typically provide a baseline for evaluating prompt-based approaches, 64% of PD studies lack non-prompt-related baselines. We provide tables and figures summarizing existing work, and reporting recommendations to guide future research contributions.
FRASIMED: a Clinical French Annotated Resource Produced through Crosslingual BERT-Based Annotation Projection
Sep 19, 2023



Natural language processing (NLP) applications such as named entity recognition (NER) for low-resource corpora do not benefit from recent advances in the development of large language models (LLMs) where there is still a need for larger annotated datasets. This research article introduces a methodology for generating translated versions of annotated datasets through crosslingual annotation projection. Leveraging a language agnostic BERT-based approach, it is an efficient solution to increase low-resource corpora with few human efforts and by only using already available open data resources. Quantitative and qualitative evaluations are often lacking when it comes to evaluating the quality and effectiveness of semi-automatic data generation strategies. The evaluation of our crosslingual annotation projection approach showed both effectiveness and high accuracy in the resulting dataset. As a practical application of this methodology, we present the creation of French Annotated Resource with Semantic Information for Medical Entities Detection (FRASIMED), an annotated corpus comprising 2'051 synthetic clinical cases in French. The corpus is now available for researchers and practitioners to develop and refine French natural language processing (NLP) applications in the clinical field (https://zenodo.org/record/8355629), making it the largest open annotated corpus with linked medical concepts in French.
InterpretTime: a new approach for the systematic evaluation of neural-network interpretability in time series classification
Feb 11, 2022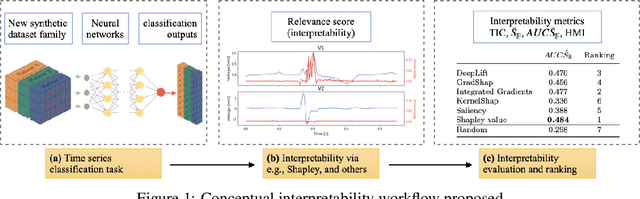
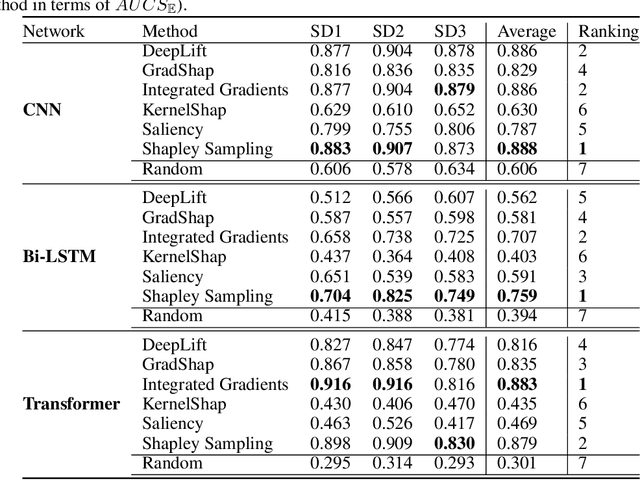
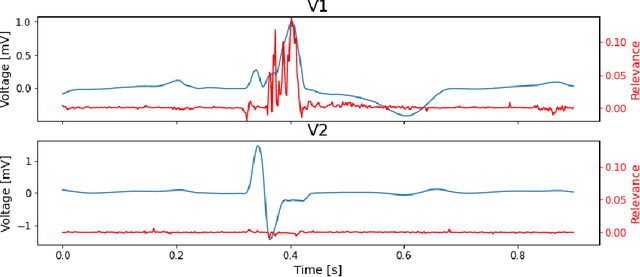
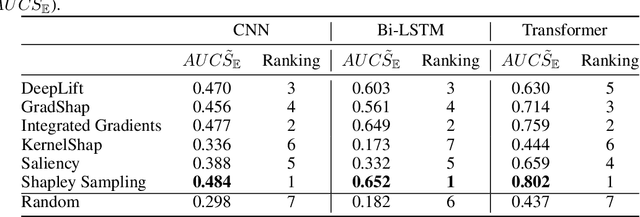
We present a novel approach to evaluate the performance of interpretability methods for time series classification, and propose a new strategy to assess the similarity between domain experts and machine data interpretation. The novel approach leverages a new family of synthetic datasets and introduces new interpretability evaluation metrics. The approach addresses several common issues encountered in the literature, and clearly depicts how well an interpretability method is capturing neural network's data usage, providing a systematic interpretability evaluation framework. The new methodology highlights the superiority of Shapley Value Sampling and Integrated Gradients for interpretability in time-series classification tasks.