 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTell me why: Visual foundation models as self-explainable classifiers
Feb 26, 2025Visual foundation models (VFMs) have become increasingly popular due to their state-of-the-art performance. However, interpretability remains crucial for critical applications. In this sense, self-explainable models (SEM) aim to provide interpretable classifiers that decompose predictions into a weighted sum of interpretable concepts. Despite their promise, recent studies have shown that these explanations often lack faithfulness. In this work, we combine VFMs with a novel prototypical architecture and specialized training objectives. By training only a lightweight head (approximately 1M parameters) on top of frozen VFMs, our approach (ProtoFM) offers an efficient and interpretable solution. Evaluations demonstrate that our approach achieves competitive classification performance while outperforming existing models across a range of interpretability metrics derived from the literature. Code is available at https://github.com/hturbe/proto-fm.
Revisiting the robustness of post-hoc interpretability methods
Jul 29, 2024

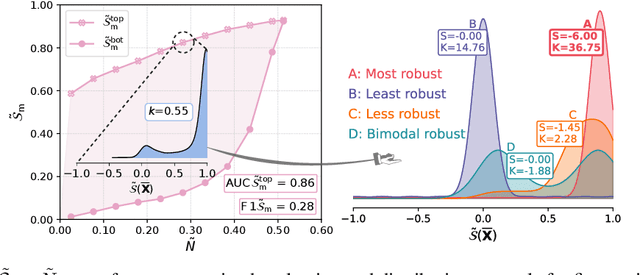
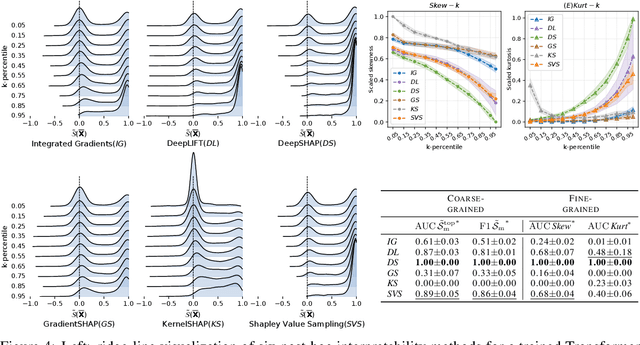
Post-hoc interpretability methods play a critical role in explainable artificial intelligence (XAI), as they pinpoint portions of data that a trained deep learning model deemed important to make a decision. However, different post-hoc interpretability methods often provide different results, casting doubts on their accuracy. For this reason, several evaluation strategies have been proposed to understand the accuracy of post-hoc interpretability. Many of these evaluation strategies provide a coarse-grained assessment -- i.e., they evaluate how the performance of the model degrades on average by corrupting different data points across multiple samples. While these strategies are effective in selecting the post-hoc interpretability method that is most reliable on average, they fail to provide a sample-level, also referred to as fine-grained, assessment. In other words, they do not measure the robustness of post-hoc interpretability methods. We propose an approach and two new metrics to provide a fine-grained assessment of post-hoc interpretability methods. We show that the robustness is generally linked to its coarse-grained performance.
ProtoS-ViT: Visual foundation models for sparse self-explainable classifications
Jun 14, 2024



Prototypical networks aim to build intrinsically explainable models based on the linear summation of concepts. However, important challenges remain in the transparency, compactness, and meaningfulness of the explanations provided by these models. This work demonstrates how frozen pre-trained ViT backbones can be effectively turned into prototypical models for both general and domain-specific tasks, in our case biomedical image classifiers. By leveraging strong spatial features combined with a novel prototypical head, ProtoS-ViT surpasses existing prototypical models showing strong performance in terms of accuracy, compactness, and explainability. Model explainability is evaluated through an extensive set of quantitative and qualitative metrics which serve as a general benchmark for the development of prototypical models. Code is available at https://github.com/hturbe/protosvit.
InterpretTime: a new approach for the systematic evaluation of neural-network interpretability in time series classification
Feb 11, 2022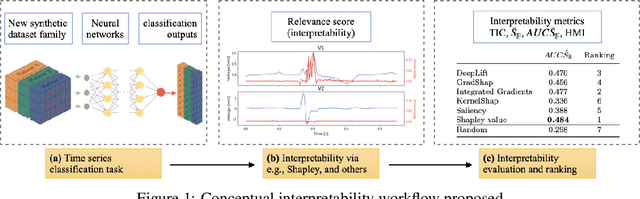
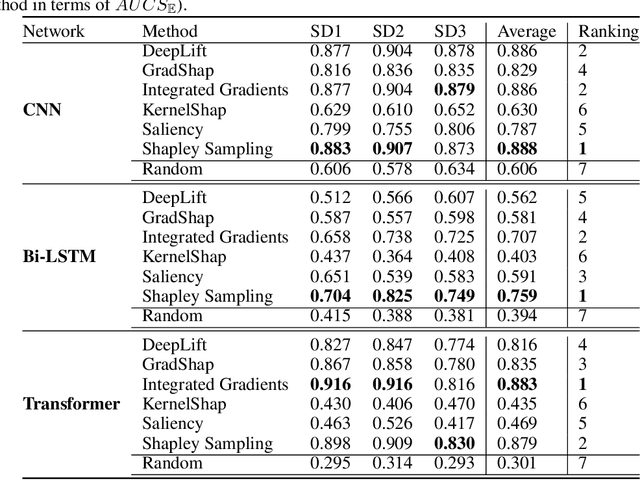
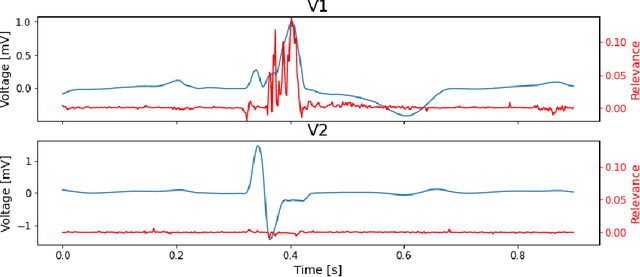
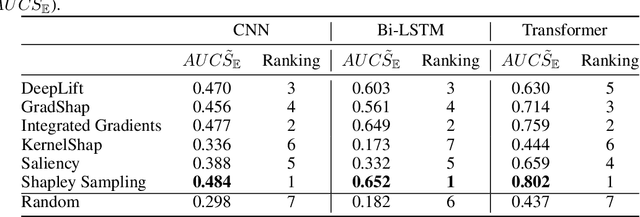
We present a novel approach to evaluate the performance of interpretability methods for time series classification, and propose a new strategy to assess the similarity between domain experts and machine data interpretation. The novel approach leverages a new family of synthetic datasets and introduces new interpretability evaluation metrics. The approach addresses several common issues encountered in the literature, and clearly depicts how well an interpretability method is capturing neural network's data usage, providing a systematic interpretability evaluation framework. The new methodology highlights the superiority of Shapley Value Sampling and Integrated Gradients for interpretability in time-series classification tasks.