Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretTime: a new approach for the systematic evaluation of neural-network interpretability in time series classification
Paper and Code
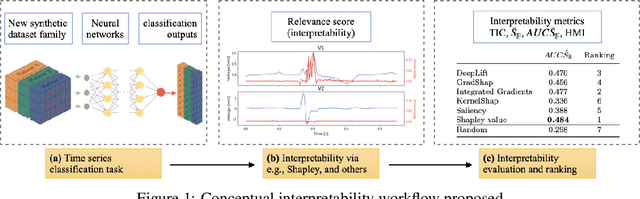
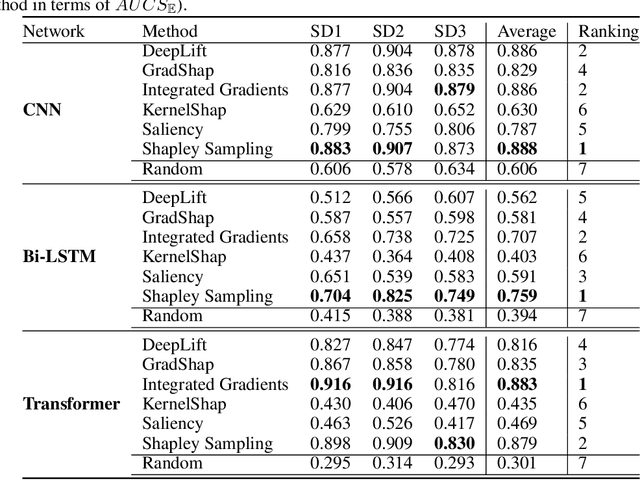
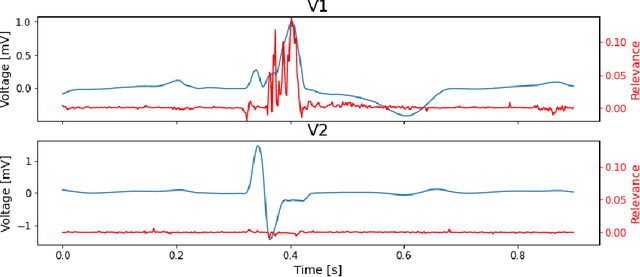
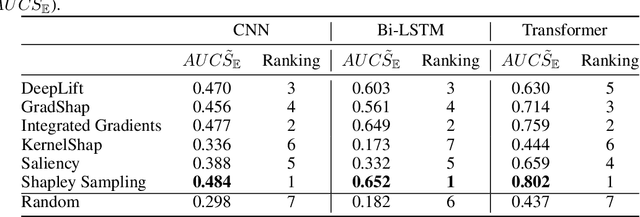
We present a novel approach to evaluate the performance of interpretability methods for time series classification, and propose a new strategy to assess the similarity between domain experts and machine data interpretation. The novel approach leverages a new family of synthetic datasets and introduces new interpretability evaluation metrics. The approach addresses several common issues encountered in the literature, and clearly depicts how well an interpretability method is capturing neural network's data usage, providing a systematic interpretability evaluation framework. The new methodology highlights the superiority of Shapley Value Sampling and Integrated Gradients for interpretability in time-series classification tasks.
View paper on