 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFRASIMED: a Clinical French Annotated Resource Produced through Crosslingual BERT-Based Annotation Projection
Sep 19, 2023



Natural language processing (NLP) applications such as named entity recognition (NER) for low-resource corpora do not benefit from recent advances in the development of large language models (LLMs) where there is still a need for larger annotated datasets. This research article introduces a methodology for generating translated versions of annotated datasets through crosslingual annotation projection. Leveraging a language agnostic BERT-based approach, it is an efficient solution to increase low-resource corpora with few human efforts and by only using already available open data resources. Quantitative and qualitative evaluations are often lacking when it comes to evaluating the quality and effectiveness of semi-automatic data generation strategies. The evaluation of our crosslingual annotation projection approach showed both effectiveness and high accuracy in the resulting dataset. As a practical application of this methodology, we present the creation of French Annotated Resource with Semantic Information for Medical Entities Detection (FRASIMED), an annotated corpus comprising 2'051 synthetic clinical cases in French. The corpus is now available for researchers and practitioners to develop and refine French natural language processing (NLP) applications in the clinical field (https://zenodo.org/record/8355629), making it the largest open annotated corpus with linked medical concepts in French.
DisMo: A Morphosyntactic, Disfluency and Multi-Word Unit Annotator. An Evaluation on a Corpus of French Spontaneous and Read Speech
Feb 08, 2018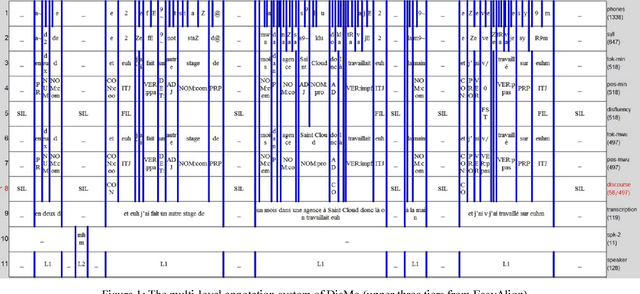
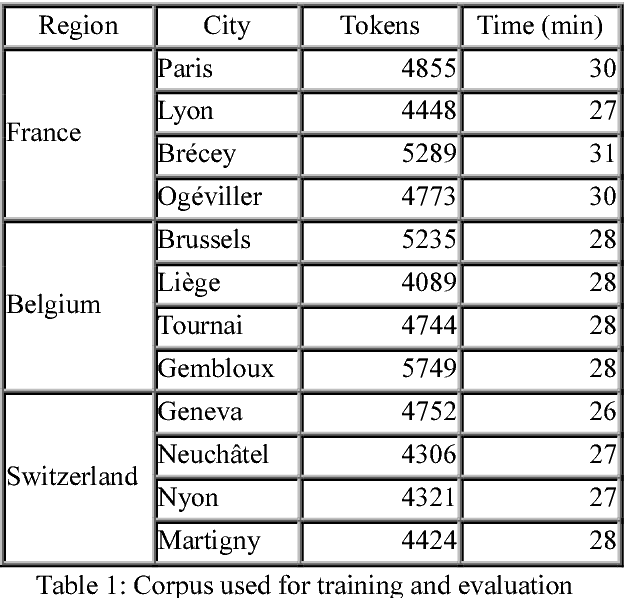
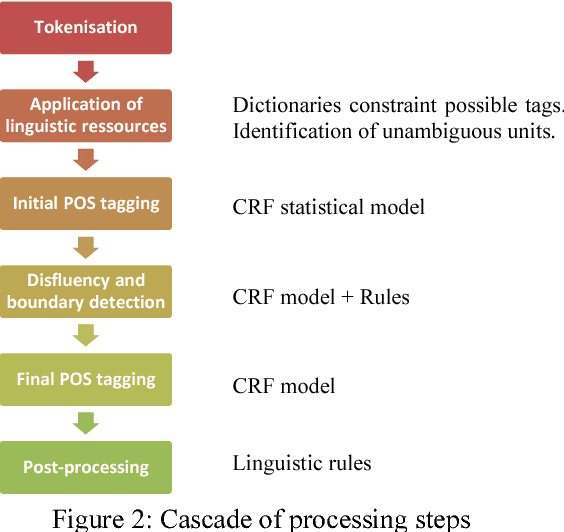
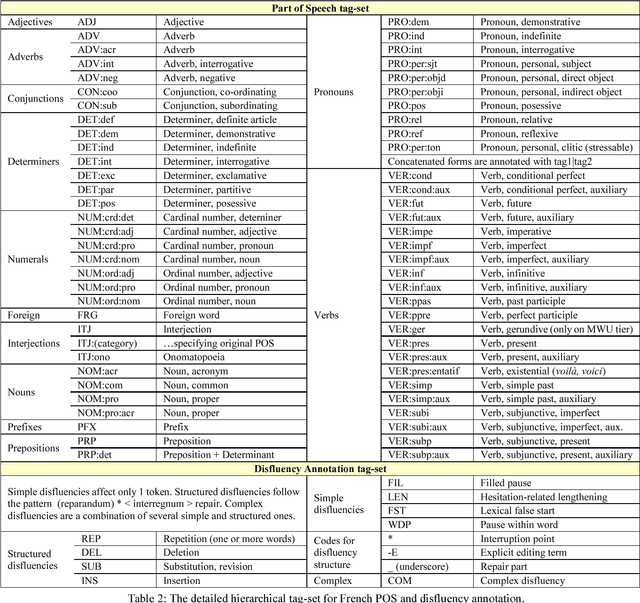
We present DisMo, a multi-level annotator for spoken language corpora that integrates part-of-speech tagging with basic disfluency detection and annotation, and multi-word unit recognition. DisMo is a hybrid system that uses a combination of lexical resources, rules, and statistical models based on Conditional Random Fields (CRF). In this paper, we present the first public version of DisMo for French. The system is trained and its performance evaluated on a 57k-token corpus, including different varieties of French spoken in three countries (Belgium, France and Switzerland). DisMo supports a multi-level annotation scheme, in which the tokenisation to minimal word units is complemented with multi-word unit groupings (each having associated POS tags), as well as separate levels for annotating disfluencies and discourse phenomena. We present the system's architecture, linguistic resources and its hierarchical tag-set. Results show that DisMo achieves a precision of 95% (finest tag-set) to 96.8% (coarse tag-set) in POS-tagging non-punctuated, sound-aligned transcriptions of spoken French, while also offering substantial possibilities for automated multi-level annotation.