 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisMo: A Morphosyntactic, Disfluency and Multi-Word Unit Annotator. An Evaluation on a Corpus of French Spontaneous and Read Speech
Feb 08, 2018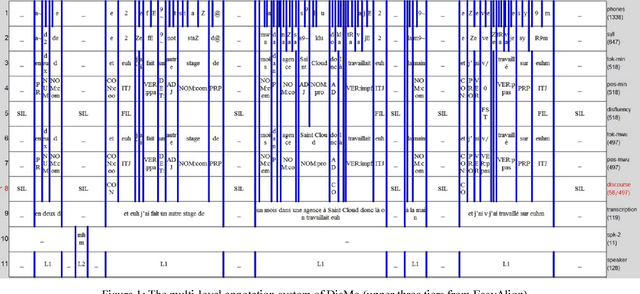
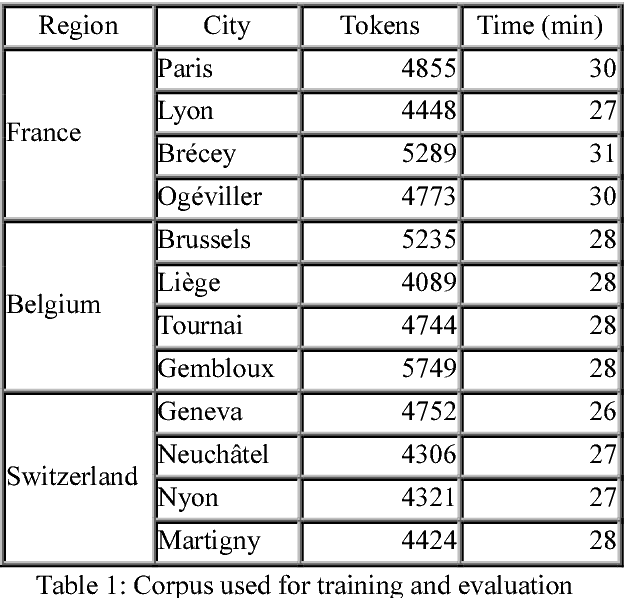
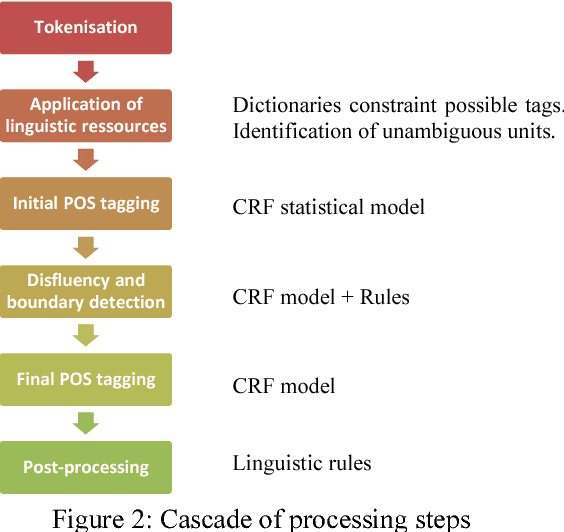
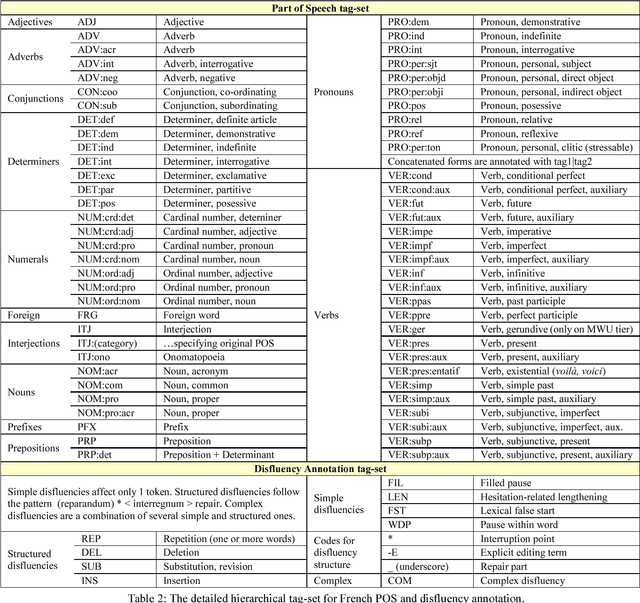
We present DisMo, a multi-level annotator for spoken language corpora that integrates part-of-speech tagging with basic disfluency detection and annotation, and multi-word unit recognition. DisMo is a hybrid system that uses a combination of lexical resources, rules, and statistical models based on Conditional Random Fields (CRF). In this paper, we present the first public version of DisMo for French. The system is trained and its performance evaluated on a 57k-token corpus, including different varieties of French spoken in three countries (Belgium, France and Switzerland). DisMo supports a multi-level annotation scheme, in which the tokenisation to minimal word units is complemented with multi-word unit groupings (each having associated POS tags), as well as separate levels for annotating disfluencies and discourse phenomena. We present the system's architecture, linguistic resources and its hierarchical tag-set. Results show that DisMo achieves a precision of 95% (finest tag-set) to 96.8% (coarse tag-set) in POS-tagging non-punctuated, sound-aligned transcriptions of spoken French, while also offering substantial possibilities for automated multi-level annotation.
Praaline: Integrating Tools for Speech Corpus Research
Feb 08, 2018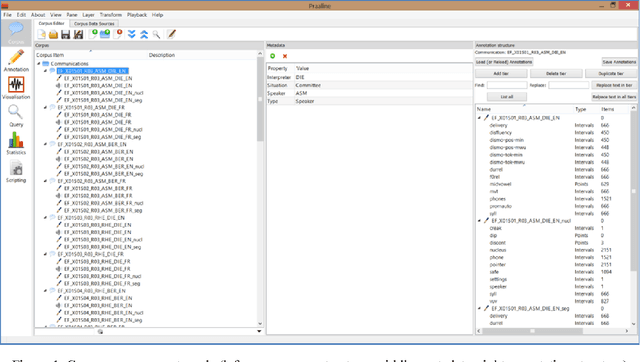
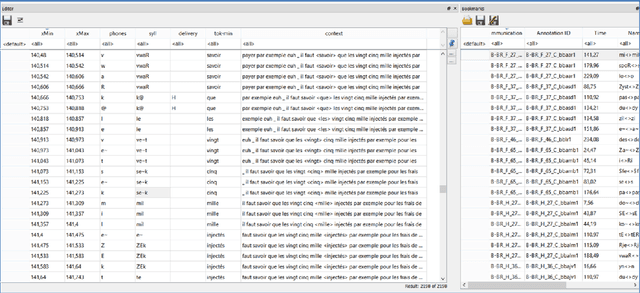
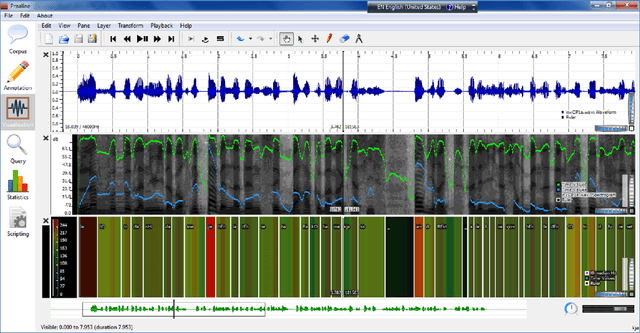
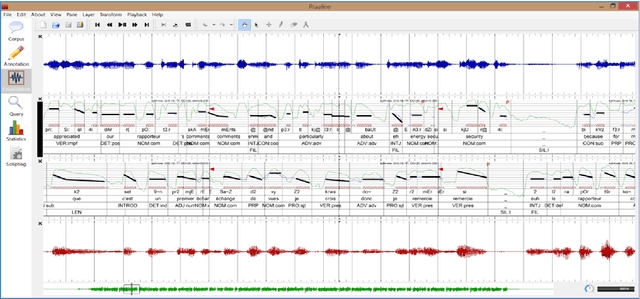
This paper presents Praaline, an open-source software system for managing, annotating, analysing and visualising speech corpora. Researchers working with speech corpora are often faced with multiple tools and formats, and they need to work with ever-increasing amounts of data in a collaborative way. Praaline integrates and extends existing time-proven tools for spoken corpora analysis (Praat, Sonic Visualiser and a bridge to the R statistical package) in a modular system, facilitating automation and reuse. Users are exposed to an integrated, user-friendly interface from which to access multiple tools. Corpus metadata and annotations may be stored in a database, locally or remotely, and users can define the metadata and annotation structure. Users may run a customisable cascade of analysis steps, based on plug-ins and scripts, and update the database with the results. The corpus database may be queried, to produce aggregated data-sets. Praaline is extensible using Python or C++ plug-ins, while Praat and R scripts may be executed against the corpus data. A series of visualisations, editors and plug-ins are provided. Praaline is free software, released under the GPL license.