 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing the Ability of Neural TTS Systems to Model Consonant-Induced F0 Perturbation
Mar 22, 2026This study proposes a segmental-level prosodic probing framework to evaluate neural TTS models' ability to reproduce consonant-induced f0 perturbation, a fine-grained segmental-prosodic effect that reflects local articulatory mechanisms. We compare synthetic and natural speech realizations for thousands of words, stratified by lexical frequency, using Tacotron 2 and FastSpeech 2 trained on the same speech corpus (LJ Speech). These controlled analyses are then complemented by a large-scale evaluation spanning multiple advanced TTS systems. Results show accurate reproduction for high-frequency words but poor generalization to low-frequency items, suggesting that the examined TTS architectures rely more on lexical-level memorization than on abstract segmental-prosodic encoding. This finding highlights a limitation in such TTS systems' ability to generalize prosodic detail beyond seen data. The proposed probe offers a linguistically informed diagnostic framework that may inform future TTS evaluation methods, and has implications for interpretability and authenticity assessment in synthetic speech.
* Accepted for publication in Computer Speech & Language
Less is more: Probabilistic reduction is best explained by small-scale predictability measures
Dec 29, 2025The primary research questions of this paper center on defining the amount of context that is necessary and/or appropriate when investigating the relationship between language model probabilities and cognitive phenomena. We investigate whether whole utterances are necessary to observe probabilistic reduction and demonstrate that n-gram representations suffice as cognitive units of planning.
Subword Tokenization Strategies for Kurdish Word Embeddings
Nov 18, 2025



We investigate tokenization strategies for Kurdish word embeddings by comparing word-level, morpheme-based, and BPE approaches on morphological similarity preservation tasks. We develop a BiLSTM-CRF morphological segmenter using bootstrapped training from minimal manual annotation and evaluate Word2Vec embeddings across comprehensive metrics including similarity preservation, clustering quality, and semantic organization. Our analysis reveals critical evaluation biases in tokenization comparison. While BPE initially appears superior in morphological similarity, it evaluates only 28.6\% of test cases compared to 68.7\% for morpheme model, creating artificial performance inflation. When assessed comprehensively, morpheme-based tokenization demonstrates superior embedding space organization, better semantic neighborhood structure, and more balanced coverage across morphological complexity levels. These findings highlight the importance of coverage-aware evaluation in low-resource language processing and offers different tokenization methods for low-resourced language processing.
Large-scale cloze evaluation reveals that token prediction tasks are neither lexically nor semantically aligned
Oct 15, 2024In this work we compare the generative behavior at the next token prediction level in several language models by comparing them to human productions in the cloze task. We find that while large models trained for longer are typically better estimators of human productions, but they reliably under-estimate the probabilities of human responses, over-rank rare responses, under-rank top responses, and produce highly distinct semantic spaces. Altogether, this work demonstrates in a tractable, interpretable domain that LM generations can not be used as replacements of or models of the cloze task.
Incorporating Annotator Uncertainty into Representations of Discourse Relations
Aug 14, 2023Annotation of discourse relations is a known difficult task, especially for non-expert annotators. In this paper, we investigate novice annotators' uncertainty on the annotation of discourse relations on spoken conversational data. We find that dialogue context (single turn, pair of turns within speaker, and pair of turns across speakers) is a significant predictor of confidence scores. We compute distributed representations of discourse relations from co-occurrence statistics that incorporate information about confidence scores and dialogue context. We perform a hierarchical clustering analysis using these representations and show that weighting discourse relation representations with information about confidence and dialogue context coherently models our annotators' uncertainty about discourse relation labels.
The distribution of discourse relations within and across turns in spontaneous conversation
Jul 07, 2023



Time pressure and topic negotiation may impose constraints on how people leverage discourse relations (DRs) in spontaneous conversational contexts. In this work, we adapt a system of DRs for written language to spontaneous dialogue using crowdsourced annotations from novice annotators. We then test whether discourse relations are used differently across several types of multi-utterance contexts. We compare the patterns of DR annotation within and across speakers and within and across turns. Ultimately, we find that different discourse contexts produce distinct distributions of discourse relations, with single-turn annotations creating the most uncertainty for annotators. Additionally, we find that the discourse relation annotations are of sufficient quality to predict from embeddings of discourse units.
Lost in Space Marking
Aug 02, 2022

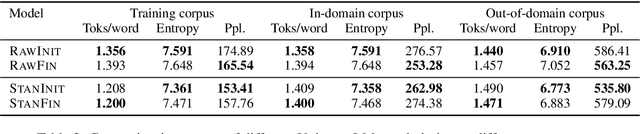
We look at a decision taken early in training a subword tokenizer, namely whether it should be the word-initial token that carries a special mark, or the word-final one. Based on surface-level considerations of efficiency and cohesion, as well as morphological coverage, we find that a Unigram LM tokenizer trained on pre-tokenized English text is better off marking the word-initial token, while one trained on raw text benefits from marking word ends. Our findings generalize across domains.
Will it Unblend?
Sep 18, 2020
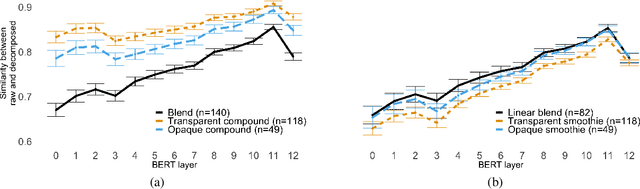
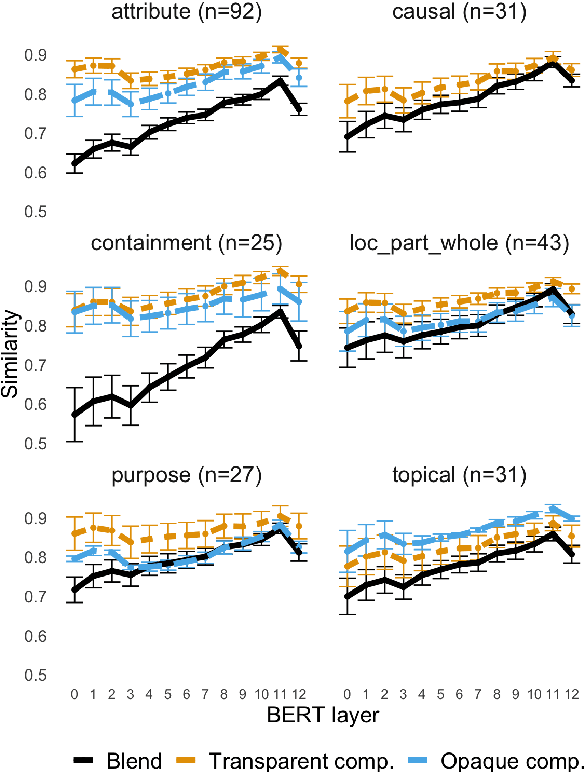

Natural language processing systems often struggle with out-of-vocabulary (OOV) terms, which do not appear in training data. Blends, such as "innoventor", are one particularly challenging class of OOV, as they are formed by fusing together two or more bases that relate to the intended meaning in unpredictable manners and degrees. In this work, we run experiments on a novel dataset of English OOV blends to quantify the difficulty of interpreting the meanings of blends by large-scale contextual language models such as BERT. We first show that BERT's processing of these blends does not fully access the component meanings, leaving their contextual representations semantically impoverished. We find this is mostly due to the loss of characters resulting from blend formation. Then, we assess how easily different models can recognize the structure and recover the origin of blends, and find that context-aware embedding systems outperform character-level and context-free embeddings, although their results are still far from satisfactory.
NYTWIT: A Dataset of Novel Words in the New York Times
Mar 06, 2020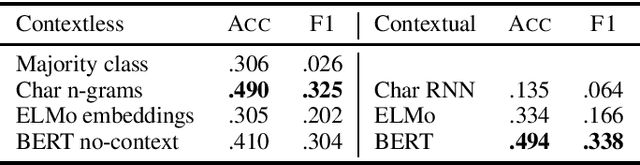
We present the New York Times Word Innovation Types dataset, or NYTWIT, a collection of over 2,500 novel English words published in the New York Times between November 2017 and March 2019, manually annotated for their class of novelty (such as lexical derivation, dialectal variation, blending, or compounding). We present baseline results for both uncontextual and contextual prediction of novelty class, showing that there is room for improvement even for state-of-the-art NLP systems. We hope this resource will prove useful for linguists and NLP practitioners by providing a real-world environment of novel word appearance.