Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLost in Space Marking
Paper and Code


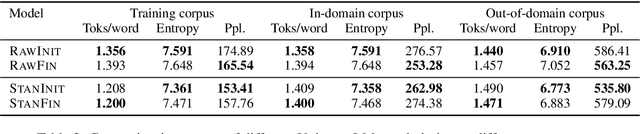
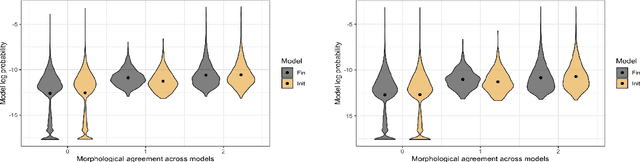
We look at a decision taken early in training a subword tokenizer, namely whether it should be the word-initial token that carries a special mark, or the word-final one. Based on surface-level considerations of efficiency and cohesion, as well as morphological coverage, we find that a Unigram LM tokenizer trained on pre-tokenized English text is better off marking the word-initial token, while one trained on raw text benefits from marking word ends. Our findings generalize across domains.
* Submission to SIGMORPHON 2021
View paper on