 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeState of NLP in Kenya: A Survey
Paper and Code
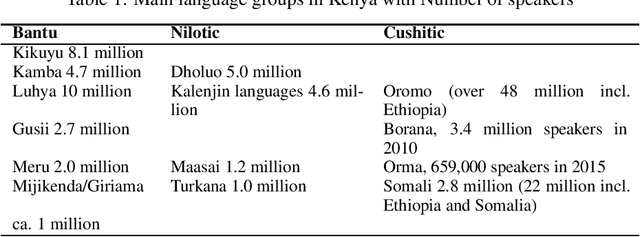
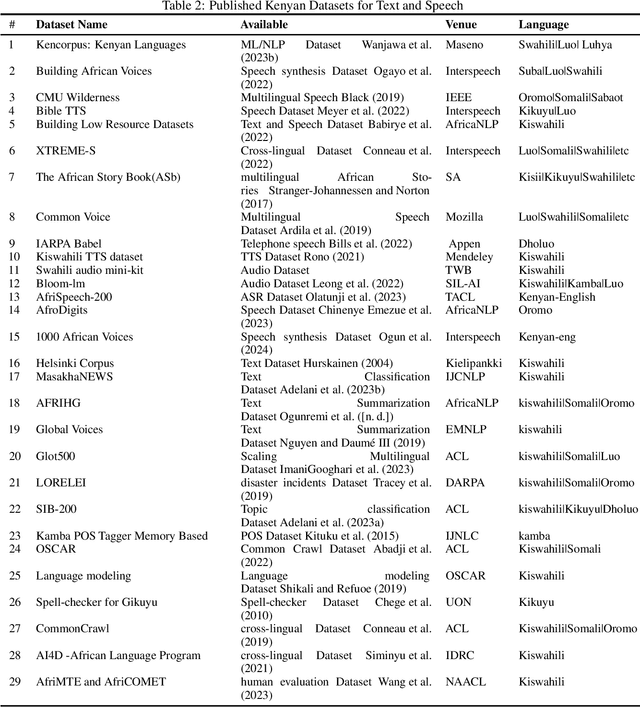
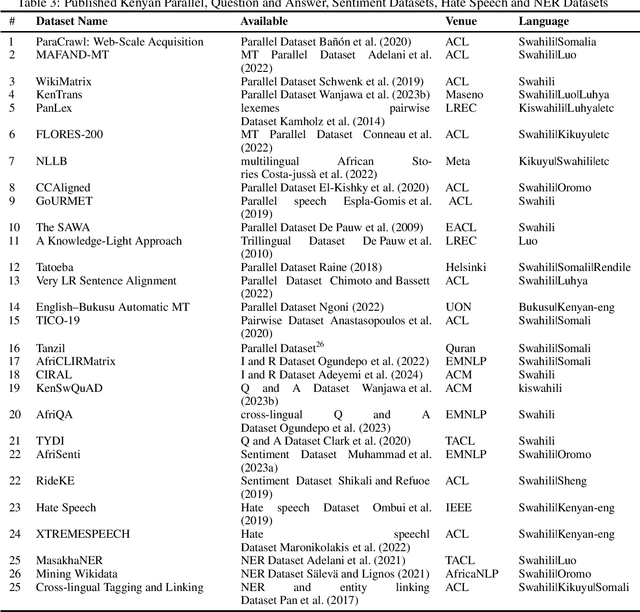
Kenya, known for its linguistic diversity, faces unique challenges and promising opportunities in advancing Natural Language Processing (NLP) technologies, particularly for its underrepresented indigenous languages. This survey provides a detailed assessment of the current state of NLP in Kenya, emphasizing ongoing efforts in dataset creation, machine translation, sentiment analysis, and speech recognition for local dialects such as Kiswahili, Dholuo, Kikuyu, and Luhya. Despite these advancements, the development of NLP in Kenya remains constrained by limited resources and tools, resulting in the underrepresentation of most indigenous languages in digital spaces. This paper uncovers significant gaps by critically evaluating the available datasets and existing NLP models, most notably the need for large-scale language models and the insufficient digital representation of Indigenous languages. We also analyze key NLP applications: machine translation, information retrieval, and sentiment analysis-examining how they are tailored to address local linguistic needs. Furthermore, the paper explores the governance, policies, and regulations shaping the future of AI and NLP in Kenya and proposes a strategic roadmap to guide future research and development efforts. Our goal is to provide a foundation for accelerating the growth of NLP technologies that meet Kenya's diverse linguistic demands.