 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Crowdsourced Election Monitoring: Construction and Evaluation of Classification Models for Multilingual and Cross-Domain Classification Settings
Paper and Code
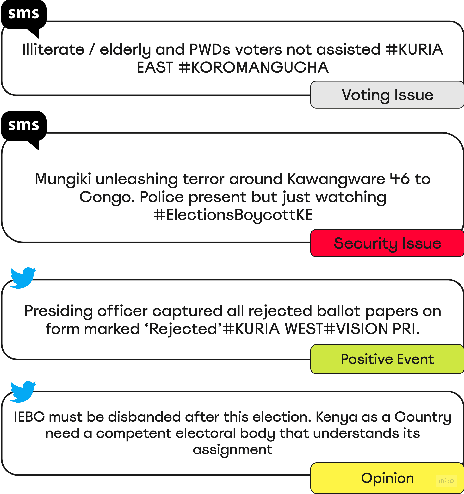
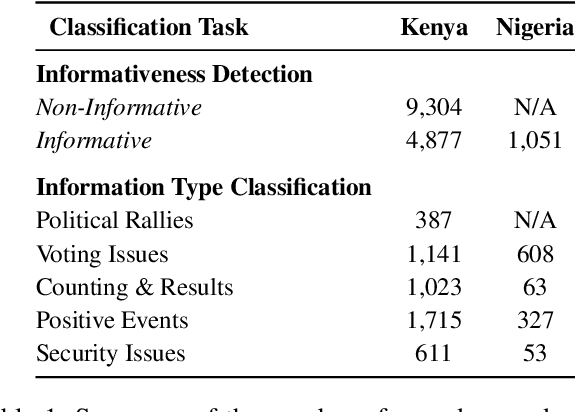
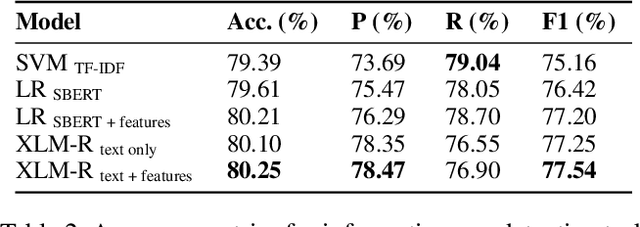
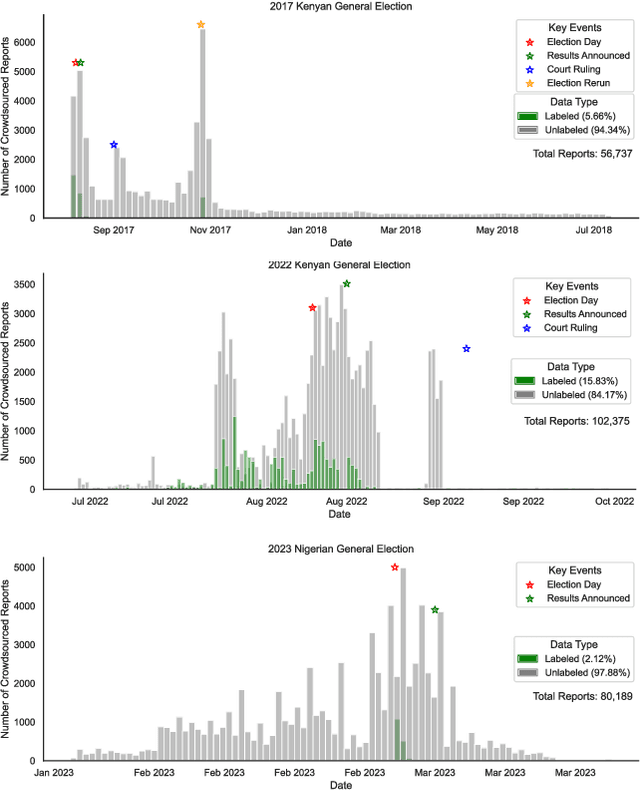
The adoption of crowdsourced election monitoring as a complementary alternative to traditional election monitoring is on the rise. Yet, its reliance on digital response volunteers to manually process incoming election reports poses a significant scaling bottleneck. In this paper, we address the challenge of scaling crowdsourced election monitoring by advancing the task of automated classification of crowdsourced election reports to multilingual and cross-domain classification settings. We propose a two-step classification approach of first identifying informative reports and then categorising them into distinct information types. We conduct classification experiments using multilingual transformer models such as XLM-RoBERTa and multilingual embeddings such as SBERT, augmented with linguistically motivated features. Our approach achieves F1-Scores of 77\% for informativeness detection and 75\% for information type classification. We conduct cross-domain experiments, applying models trained in a source electoral domain to a new target electoral domain in zero-shot and few-shot classification settings. Our results show promising potential for model transfer across electoral domains, with F1-Scores of 59\% in zero-shot and 63\% in few-shot settings. However, our analysis also reveals a performance bias in detecting informative English reports over Swahili, likely due to imbalances in the training data, indicating a need for caution when deploying classification models in real-world election scenarios.