 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIgbo-English Machine Translation: An Evaluation Benchmark
Paper and Code
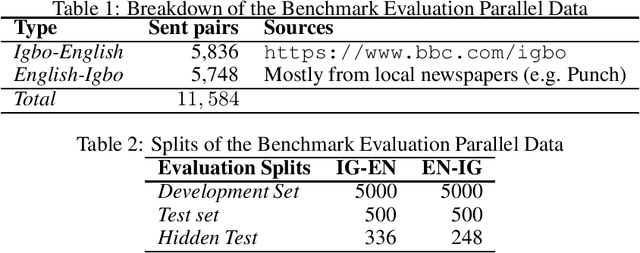

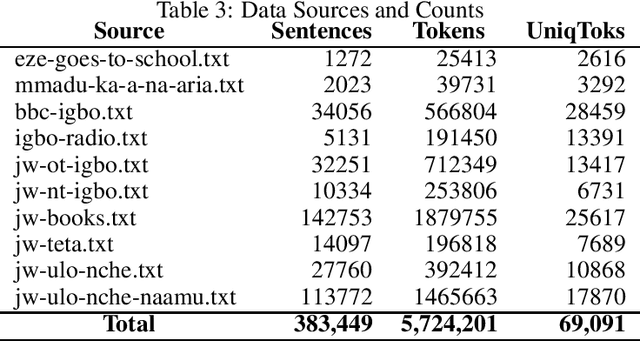
Although researchers and practitioners are pushing the boundaries and enhancing the capacities of NLP tools and methods, works on African languages are lagging. A lot of focus on well resourced languages such as English, Japanese, German, French, Russian, Mandarin Chinese etc. Over 97% of the world's 7000 languages, including African languages, are low resourced for NLP i.e. they have little or no data, tools, and techniques for NLP research. For instance, only 5 out of 2965, 0.19% authors of full text papers in the ACL Anthology extracted from the 5 major conferences in 2018 ACL, NAACL, EMNLP, COLING and CoNLL, are affiliated to African institutions. In this work, we discuss our effort toward building a standard machine translation benchmark dataset for Igbo, one of the 3 major Nigerian languages. Igbo is spoken by more than 50 million people globally with over 50% of the speakers are in southeastern Nigeria. Igbo is low resourced although there have been some efforts toward developing IgboNLP such as part of speech tagging and diacritic restoration