 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNUIG-Shubhanker@Dravidian-CodeMix-FIRE2020: Sentiment Analysis of Code-Mixed Dravidian text using XLNet
Oct 15, 2020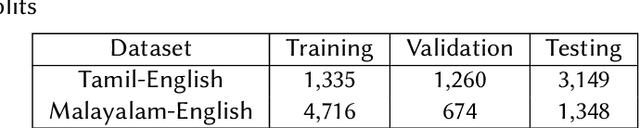
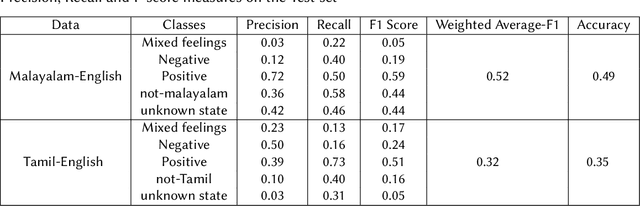
Social media has penetrated into multilingual societies, however most of them use English to be a preferred language for communication. So it looks natural for them to mix their cultural language with English during conversations resulting in abundance of multilingual data, call this code-mixed data, available in todays' world.Downstream NLP tasks using such data is challenging due to the semantic nature of it being spread across multiple languages.One such Natural Language Processing task is sentiment analysis, for this we use an auto-regressive XLNet model to perform sentiment analysis on code-mixed Tamil-English and Malayalam-English datasets.
USFD at KBP 2011: Entity Linking, Slot Filling and Temporal Bounding
Mar 22, 2012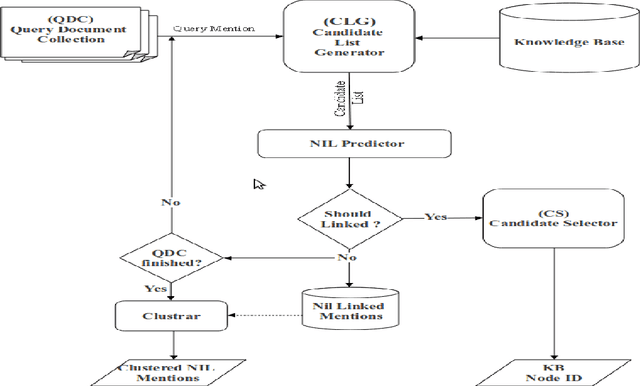
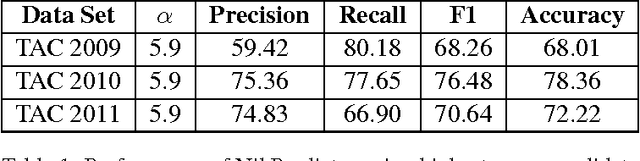
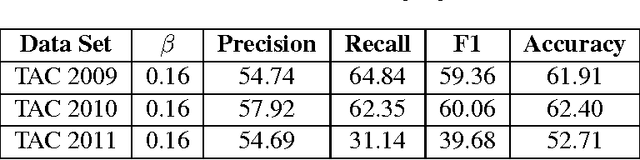

This paper describes the University of Sheffield's entry in the 2011 TAC KBP entity linking and slot filling tasks. We chose to participate in the monolingual entity linking task, the monolingual slot filling task and the temporal slot filling tasks. We set out to build a framework for experimentation with knowledge base population. This framework was created, and applied to multiple KBP tasks. We demonstrated that our proposed framework is effective and suitable for collaborative development efforts, as well as useful in a teaching environment. Finally we present results that, while very modest, provide improvements an order of magnitude greater than our 2010 attempt.