 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFindings of the Sentiment Analysis of Dravidian Languages in Code-Mixed Text
Nov 18, 2021
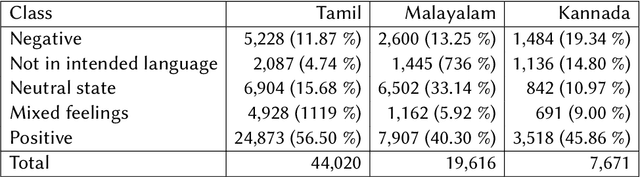
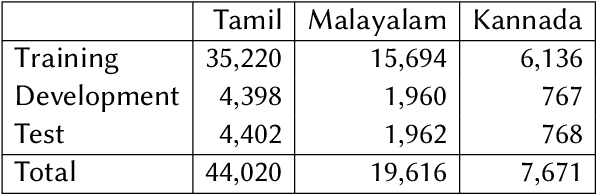
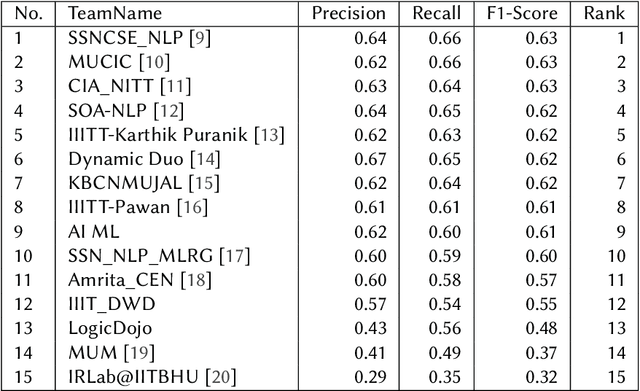
We present the results of the Dravidian-CodeMix shared task held at FIRE 2021, a track on sentiment analysis for Dravidian Languages in Code-Mixed Text. We describe the task, its organization, and the submitted systems. This shared task is the continuation of last year's Dravidian-CodeMix shared task held at FIRE 2020. This year's tasks included code-mixing at the intra-token and inter-token levels. Additionally, apart from Tamil and Malayalam, Kannada was also introduced. We received 22 systems for Tamil-English, 15 systems for Malayalam-English, and 15 for Kannada-English. The top system for Tamil-English, Malayalam-English and Kannada-English scored weighted average F1-score of 0.711, 0.804, and 0.630, respectively. In summary, the quality and quantity of the submission show that there is great interest in Dravidian languages in code-mixed setting and state of the art in this domain still needs more improvement.
NUIG-Shubhanker@Dravidian-CodeMix-FIRE2020: Sentiment Analysis of Code-Mixed Dravidian text using XLNet
Oct 15, 2020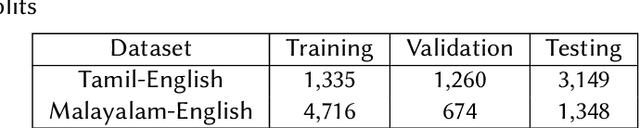
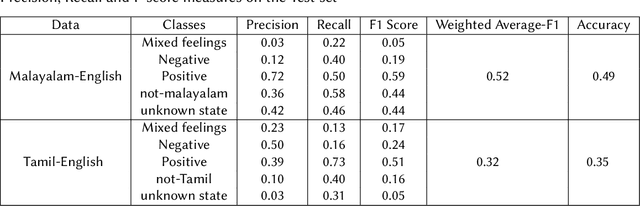
Social media has penetrated into multilingual societies, however most of them use English to be a preferred language for communication. So it looks natural for them to mix their cultural language with English during conversations resulting in abundance of multilingual data, call this code-mixed data, available in todays' world.Downstream NLP tasks using such data is challenging due to the semantic nature of it being spread across multiple languages.One such Natural Language Processing task is sentiment analysis, for this we use an auto-regressive XLNet model to perform sentiment analysis on code-mixed Tamil-English and Malayalam-English datasets.