 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnTDA: Entity-to-Text based Data Augmentation Approach for Named Entity Recognition Tasks
Paper and Code
Oct 19, 2022
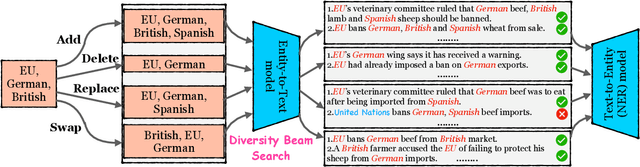
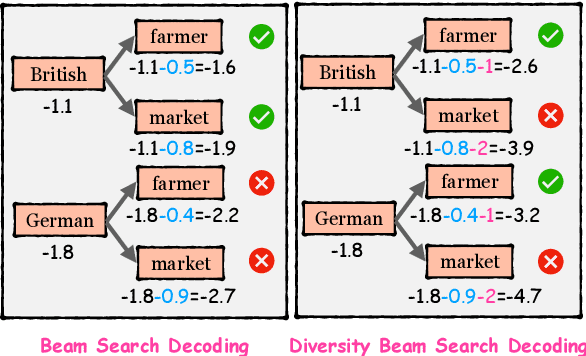
Data augmentation techniques have been used to improve the generalization capability of models in the named entity recognition (NER) tasks. Existing augmentation methods either manipulate the words in the original text that require hand-crafted in-domain knowledge, or leverage generative models which solicit dependency order among entities. To alleviate the excessive reliance on the dependency order among entities in existing augmentation paradigms, we develop an entity-to-text instead of text-to-entity based data augmentation method named: EnTDA to decouple the dependencies between entities by adding, deleting, replacing and swapping entities, and adopt these augmented data to bootstrap the generalization ability of the NER model. Furthermore, we introduce a diversity beam search to increase the diversity of the augmented data. Experiments on thirteen NER datasets across three tasks (flat NER, nested NER, and discontinuous NER) and two settings (full data NER and low resource NER) show that EnTDA could consistently outperform the baselines.